.png&blockId=1be7fa62-695a-490b-8082-af8e2633614f&width=3600)

Summary
•
Authors proposed a framework called D-SLA that aims to learn the exact discrepancy between the original and the perturbed graphs.
•
Three major components
1.
Learn to distinguish whether each graph is the original graph or the perturbed one.
2.
Capture the amount of discrepancy for each perturbed graph (using edit distance)
3.
Learn relative discrepancy with other graphs
Preliminaries
Graph Neural Networks (GNN)
1.
Aggregate the features from its neighbors
2.
Combining the aggregated message
Variants of Update & Aggregate functions
•
Graph Convolution Network (GCN)
General convolution operation + Mean aggregation
•
GraphSAGE
Concatenate representations of neighbors with its own representation when updating
•
Graph Attention Network (GAT)
Considers the relative importance among neighboring nodes when aggregation
•
Graph Isomorphism Network (GIN)
Sum aggregation
Self-supervised learning for graphs (GSL)
Aims to learn a good representation of the graphs in an unsupervised manner.
→ Transfer this knowledge to downstream tasks.
Most prevalent framework for GSL
•
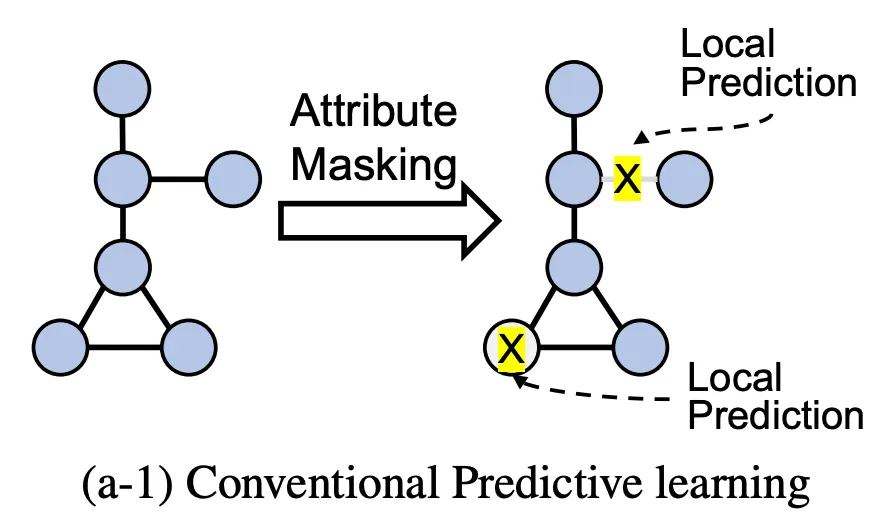
Predictive learning (PL)
Aims to learn contextual relationships by predicting sub-graphical features (nodes, edges, subgraphs)
◦
predict the attributes of masked nodes
◦
predict the presence of an edge or a path
◦
predict the generative sequence, contextual property, and motifs
But predictive learning may not capture the global structures and/or semantics of graphs.
•
Contrastive learning (CL)
Aims to capture global level information.
◦
Early CL learn the similarity between the entire graph and its substructure.
◦
Others include attribute masking, edge perturbation, and subgraph sampling.
◦
Recent CL adversarial methods generate positive examples either by adaptively removing the edges or by adjusting the attributes.
But CL may not distinguish two topologically similar graphs yet having completely different properties.
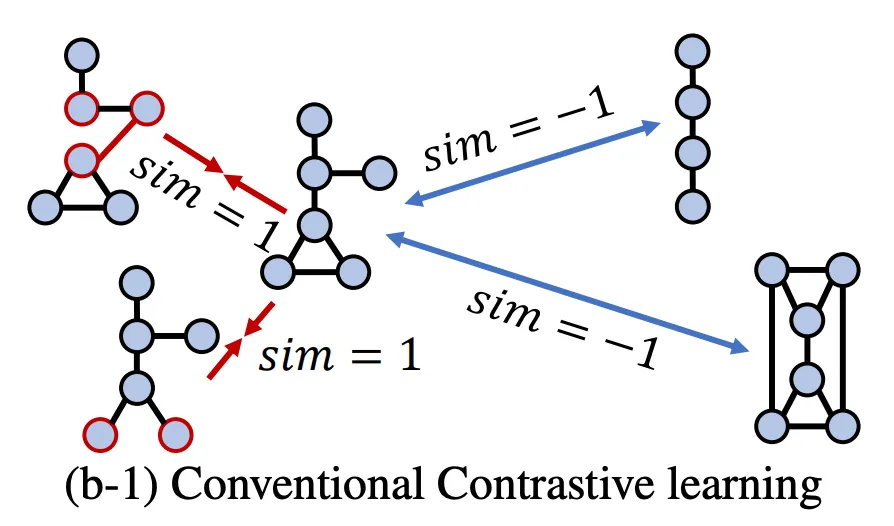
Minimize
◦
: original graph
◦
: perturbed graphs
◦
: other graph in the same batch with the , a.k.a. negative graph
◦
positive pair: ; negative pair:
◦
: similarity function between two graphs → distance or cosine similarity
→ similarity of positive pair , similarity of negative pair
Discrepancy Learning
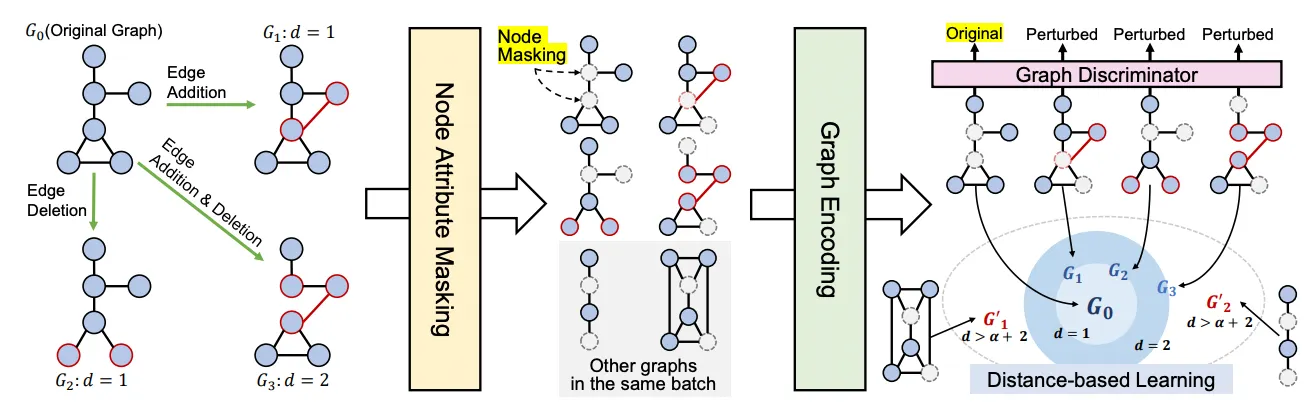
1.
Discriminate original vs perturbed
Perturbed graph could be semantically incorrect!
→ Embed perturbed graph apart from original.
Intuitively,
•
large value of for the original graph
•
small value of for the perturbed graphs
How to perturb?
Aim at perturbed graph to be semantically incorrect
1.
Remove or add a small number of edges
Manipulate the edge set by removing existing edges + adding new edges on
2.
Mask node attributes
Randomly mask the node attributes on for both original and perturbed graphs
(to make it more difficult to distinguish between them)
Personal opinion
•
The real usage of discriminator loss will be to push original & perturbed graph apart, while applying edit distance loss.
2.
Discrepancy with Edit distance
How dissimilar?
•
Usually, we need to measure the graph distance, such as edit distance.
Edit distance: number of insertion, deletion, and substitution operations for nodes & edges to transform one graph from another. → NP hard!
•
But we know the exact number of perturbations for each graphs
→ use it as distance.
measures the embedding level differences between graphs with L2 norm.
: edit distance (number of perturbations)
The trivial solution for the edit distance loss is . But because of the discriminator loss, this is not possible.
3.
Relative discrepancy learning with other graphs
Assumption:
Distance between original and negative graphs in the same batch is larger than the distance between the original and perturbed graphs with some amount of margin.
Formally,
: distance between original and its perturbed graphs
: distance between original and negative graphs
Intuitively, !