

계정 생성 및 GPU 인스턴스 할당


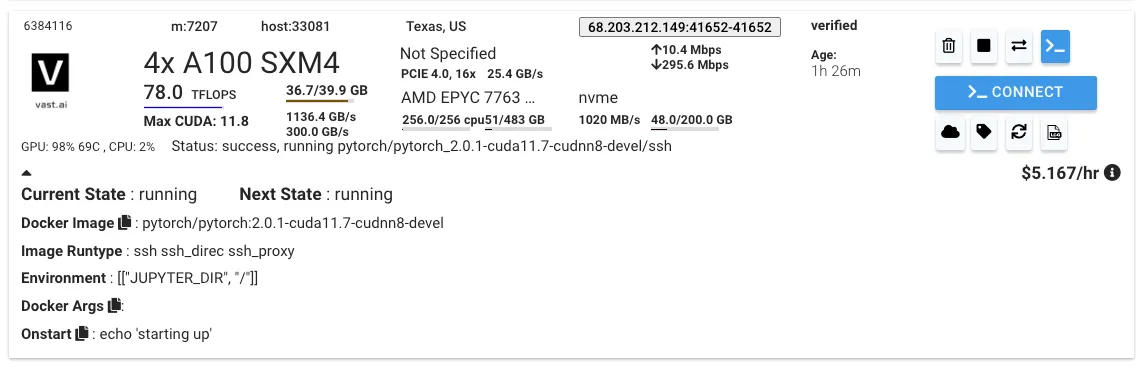
인스턴스 내 환경 설정
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA/
conda create -n llava python=3.10 -y
source activate llava
pip install --upgrade pip
pip install -e .
pip install ninja
pip install flash-attn==1.0.2
Bash
복사
데이터셋 업로드
•
서버
mkdir /root/dataset/CC3M_pretrain
Bash
복사
•
이미지 파일이 있는 local
scp -P [port_num] images.zip root@68.xxx.xxx.xxx:/root/dataset/CC3M_pretrain
Bash
복사
•
서버
apt install unzip
cd /root/dataset/CC3M_pretrain
unzip -qq images.zip
Bash
복사
Pre-Training 파일
apt install vim
vim ./scripts/pretraining.sh
Bash
복사
•
pretraining.sh
#!/bin/bash
WEIGHT_VERSION=$1
# --model_name_or_path ./checkpoints/llama-vicuna-7b \
# --model_name_or_path junelee/ko_vicuna_7b \ nlpai-lab/kullm-polyglot-12.8b-v2
# Pretraining (2 hours)
torchrun --nnodes=1 --nproc_per_node=1 --master_port=25001 \
llava/train/train_mem.py \
--model_name_or_path junelee/ko_vicuna_7b \
--version $WEIGHT_VERSION \
--data_path /root/dataset/ko_chat.json \
--image_folder /root/dataset/CC3M_pretrain \
--vision_tower openai/clip-vit-large-patch14 \
--tune_mm_mlp_adapter True \
--mm_vision_select_layer -2 \
--mm_use_im_start_end \
--bf16 True \
--output_dir ./checkpoints/kollava-lightning-7b-pretrain \
--num_train_epochs 1 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 600 \
--save_total_limit 1 \
--learning_rate 2e-3 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--lazy_preprocess True \
--report_to wandb
# Extract projector features
python scripts/extract_mm_projector.py \
--model_name_or_path ./checkpoints/kollava-lightning-7b-pretrain \
--output ./checkpoints/mm_projector/kollava-lightning-7b-pretrain.bin
Bash
복사
Pretrain 학습 실행
sh scripts/pretraining.sh v0
Bash
복사
•
wandb 설정하라고 뜸
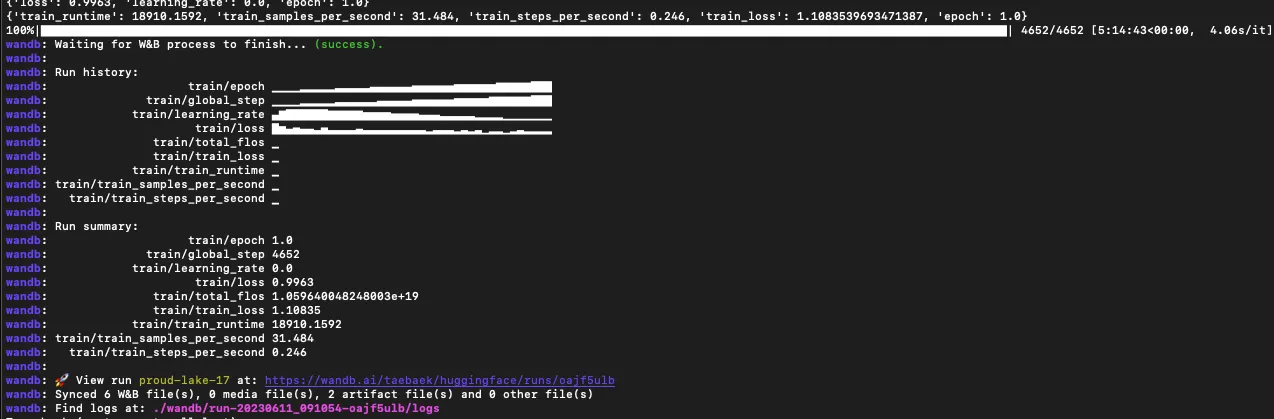
Finetune
•
llava/model/llava.py 수정 필요
◦
cur_image_
#!/bin/bash
WEIGHT_VERSION=$1
# Pretraining (2 hours)
#torchrun --nnodes=1 --nproc_per_node=4 --master_port=25001 \
# llava/train/train_mem.py \
# --model_name_or_path junelee/ko_vicuna_7b \
# --version $WEIGHT_VERSION \
# --data_path /root/dataset/ko_chat.json \
# --image_folder /root/dataset/CC3M_pretrain \
# --vision_tower openai/clip-vit-large-patch14 \
# --tune_mm_mlp_adapter True \
# --mm_vision_select_layer -2 \
# --mm_use_im_start_end \
# --bf16 True \
# --output_dir ./checkpoints/kollava-lightning-7b-pretrain \
# --num_train_epochs 1 \
# --per_device_train_batch_size 32 \
# --per_device_eval_batch_size 4 \
# --gradient_accumulation_steps 1 \
# --evaluation_strategy "no" \
# --save_strategy "steps" \
# --save_steps 2400 \
# --save_total_limit 1 \
# --learning_rate 2e-3 \
# --weight_decay 0. \
# --warmup_ratio 0.03 \
# --lr_scheduler_type "cosine" \
# --logging_steps 1 \
# --tf32 True \
# --model_max_length 2048 \
# --gradient_checkpointing True \
# --dataloader_num_workers 4 \
# --lazy_preprocess True \
# --report_to wandb
# Extract projector features
#python scripts/extract_mm_projector.py --model_name_or_path ./checkpoints/kollava-lightning-7b-pretrain --output ./checkpoints/mm_projector/kollava-lightning-7b-pretrain.bin
# Visual instruction tuning (1 hour)
torchrun --nnodes=1 --nproc_per_node=4 --master_port=25001 \
llava/train/train_mem.py \
--model_name_or_path junelee/ko_vicuna_7b \
--version $WEIGHT_VERSION \
--data_path /root/dataset/ko_llava_instruct_150k.json \
--image_folder /root/dataset/train2014 \
--vision_tower openai/clip-vit-large-patch14 \
--pretrain_mm_mlp_adapter ./checkpoints/mm_projector/kollava-lightning-7b-pretrain.bin \
--mm_vision_select_layer -2 \
--mm_use_im_start_end True \
--bf16 True \
--output_dir ./checkpoints \
--num_train_epochs 1 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 5000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--lazy_preprocess True \
--report_to wandb
~
Bash
복사
File "/root/LLaVA/llava/model/llava.py", line 147, in forward
cur_image_features = image_features[cur_image_idx]