•
일부 노드의 라벨이 주어졌을 때 다른 노드들의 값을 어떻게 예측할 것인가?
→ Message Passing
•
Correlation을 이용한다.
•
비슷한 노드들은 연결되어 있다.
•
모든 노드들을 라벨링하는 collective classification을 활용한다.
•
네트워크엔 homophily가 있다.
•
이 correlation을 노드를 예측하는데 어떻게 반영할 것인가?
Semi-supervised binary node classification
Probabilistic Relational Classifier
•
주변 노드들의 probability의 가중합으로 probability를 구함
•
초기엔 0.5로 initialize
•
random order로 unlabeled node의 값을 update



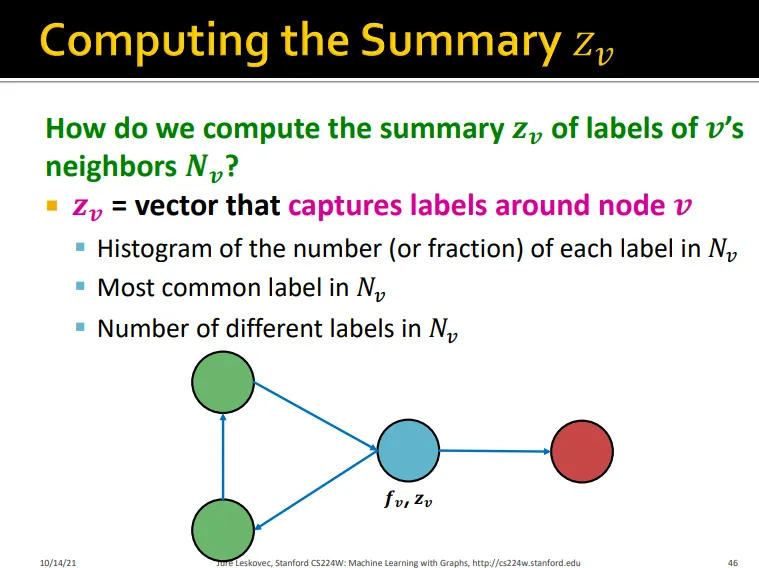
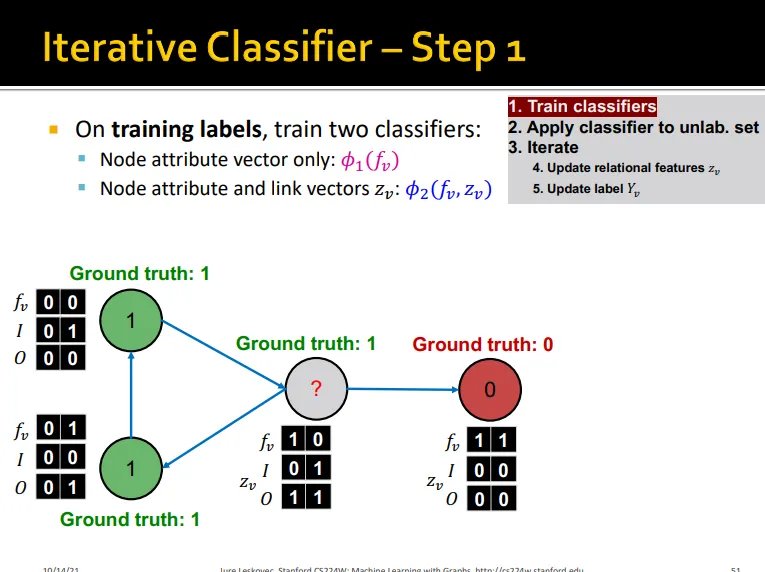
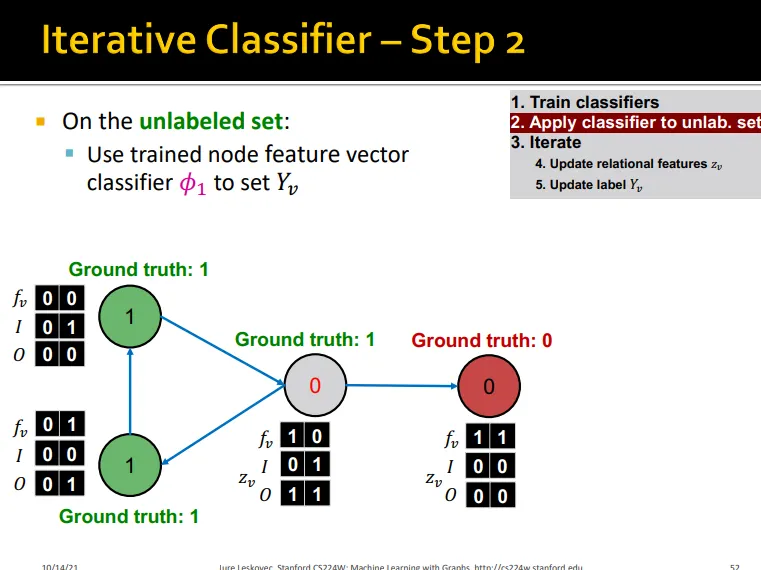
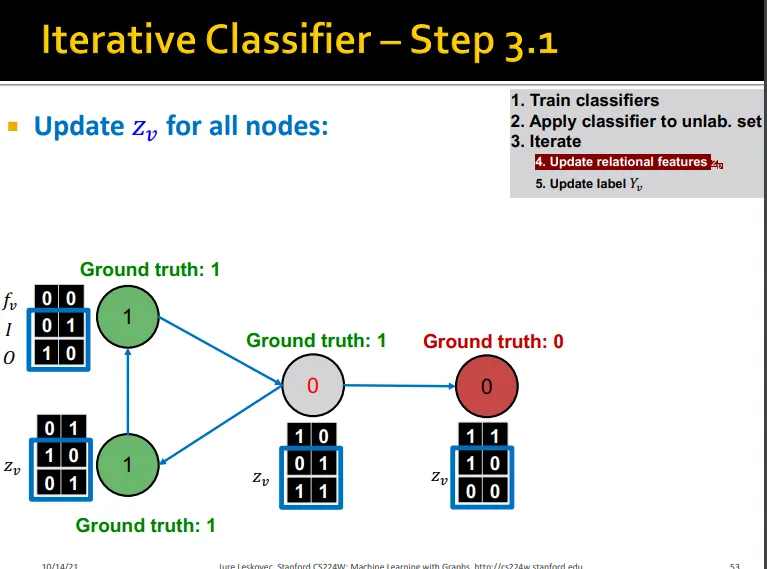
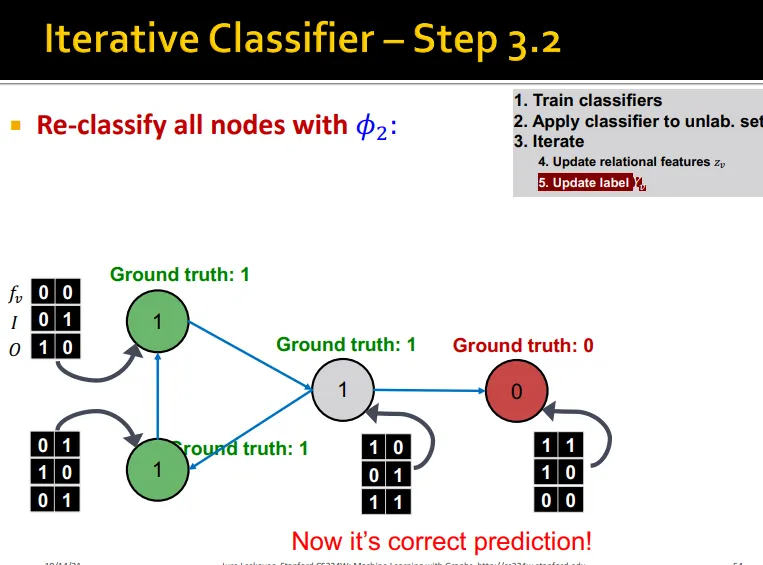
Iterative Classification
•
relational classifier는 node attribute을 사용하지 않음
•
이를 leverage하기 위함
•
두 가지 종류의 classifier 학습
1.
예측하고자 하는 node v의 node feature를 이용하여 predicting하는 base classifier
2.
v의 node feature vector와 v의 이웃 노드들의 label summary를 이용하여 predicting하는 relational classifier


•
Iteration 수행
1.
base classifier로 update
2.
로 update
3.
class label이 stabilize 될 때까지 or max.iteration에 도달할 때까지 수행
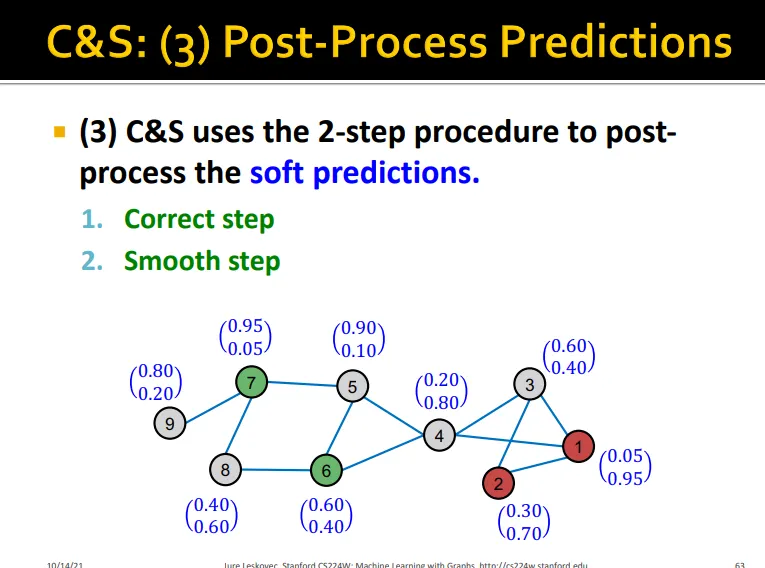
Collective Classification: Correct & Smooth
1.
base prediction 학습
2.
base predictor로 모든 노드의 soft label(class probability) predict
3.
graph structure를 이용해 prediction을 post-process하여 final prediction을 얻음
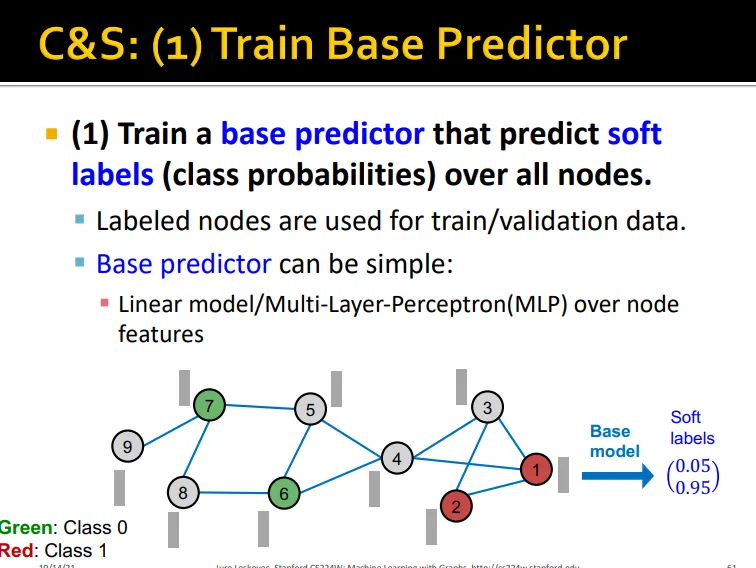
•
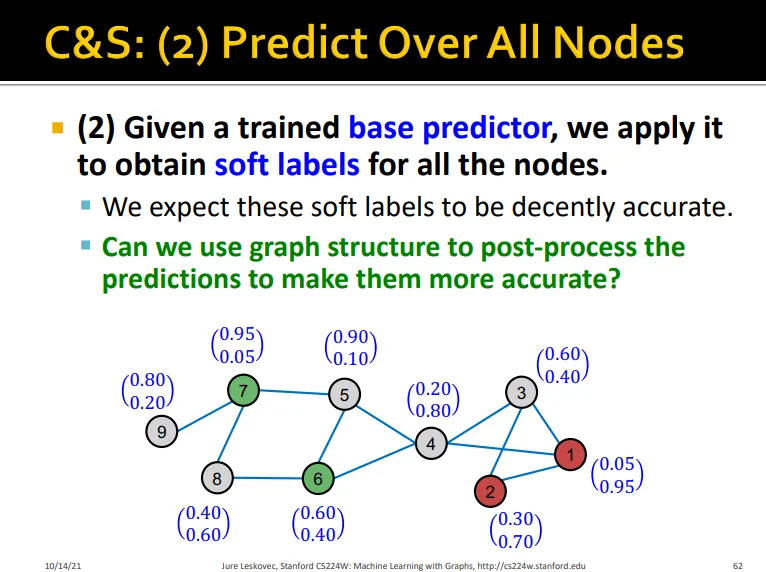
Labeled node를 이용해 base predictor 학습
•
base predictor로 예측
•
하지만 이 값은 정확하지 않음
•
graph structure를 이용해 post-process하기로 함
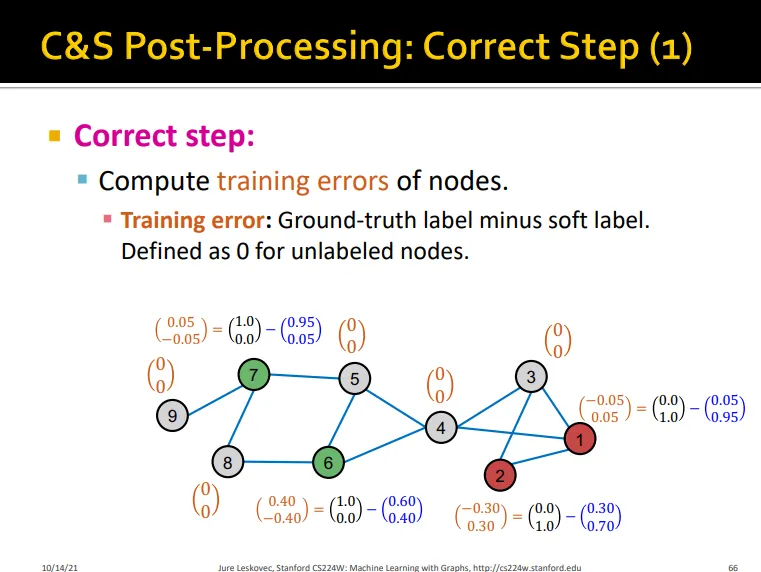
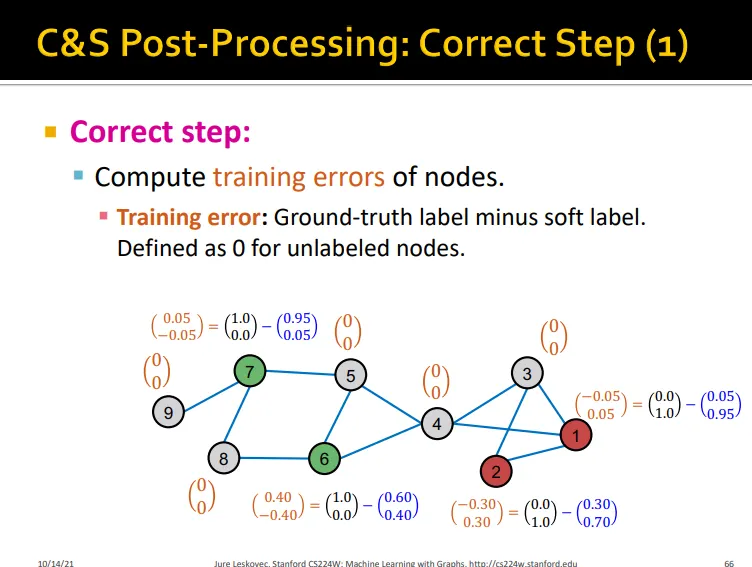
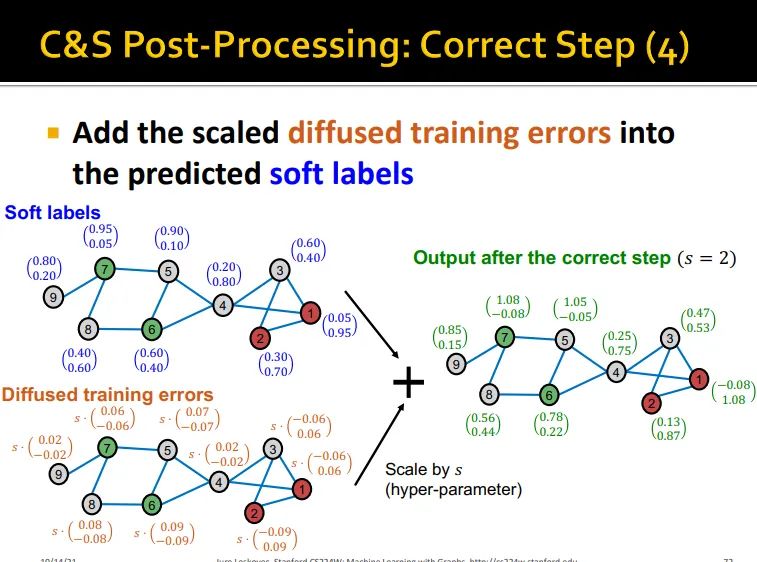
1. Correct Step
•
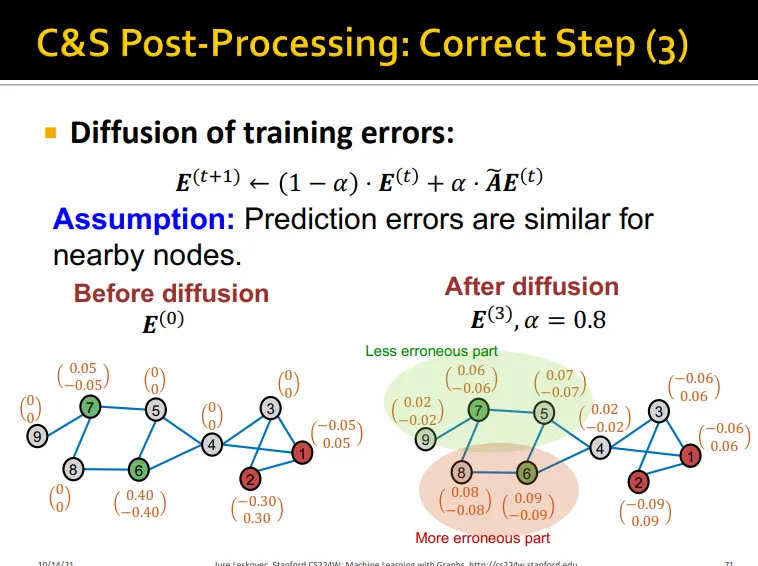
Assumption: node u의 prediction의 error의 u의 이웃노드들의 error와 비슷하게 발생함
•
training error의 전파를 이용함
•
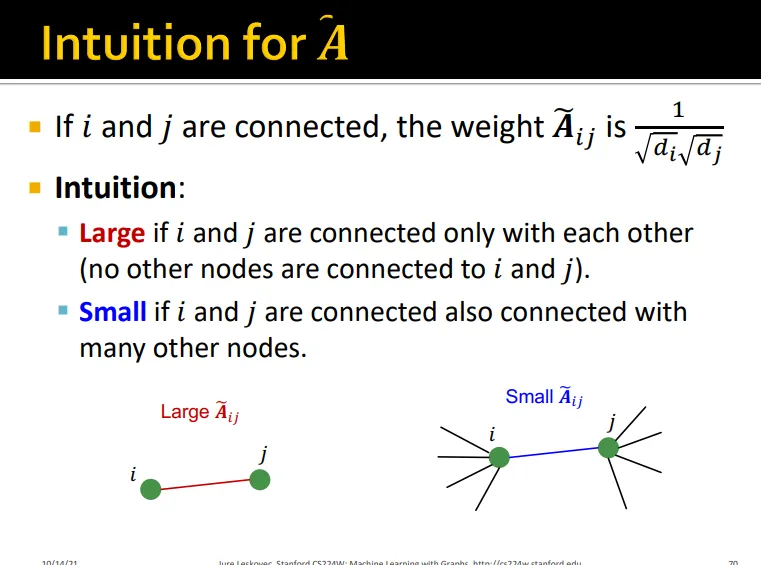
diffusion matrix 를 이용하여 degree 값을 normalize하여 update
•
자기 자신의 training error + 이웃 노드의 training error normalize값 → error update
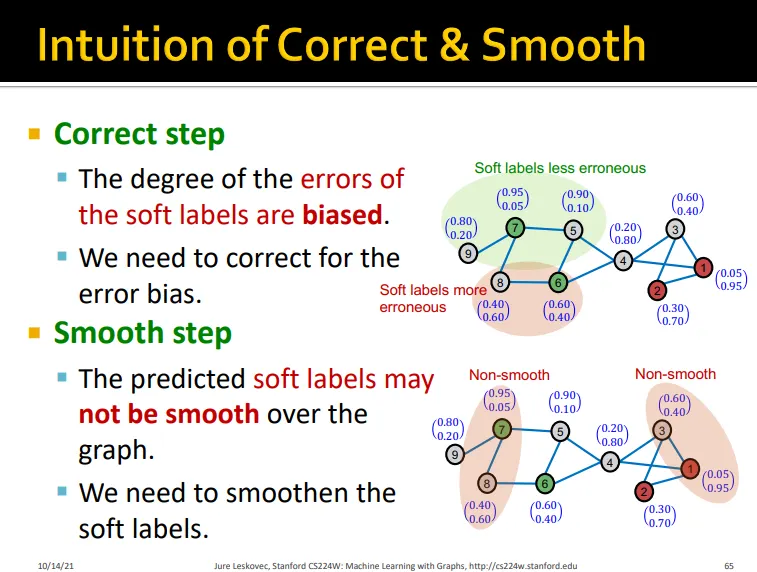

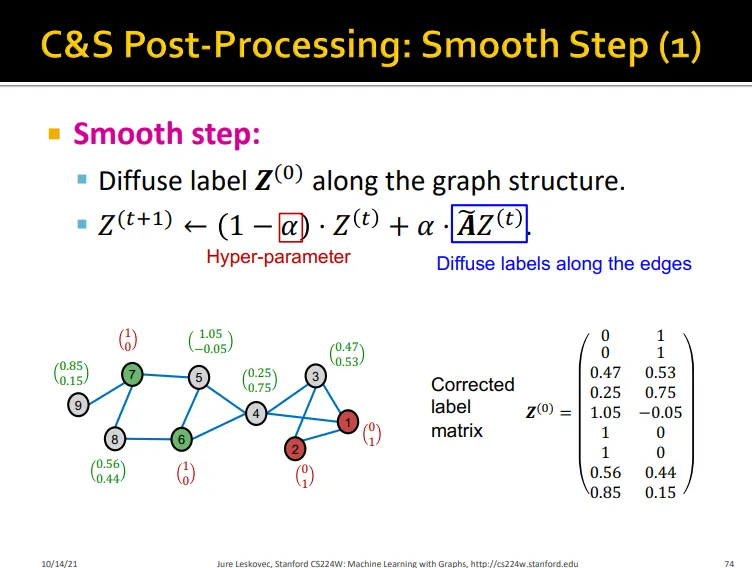
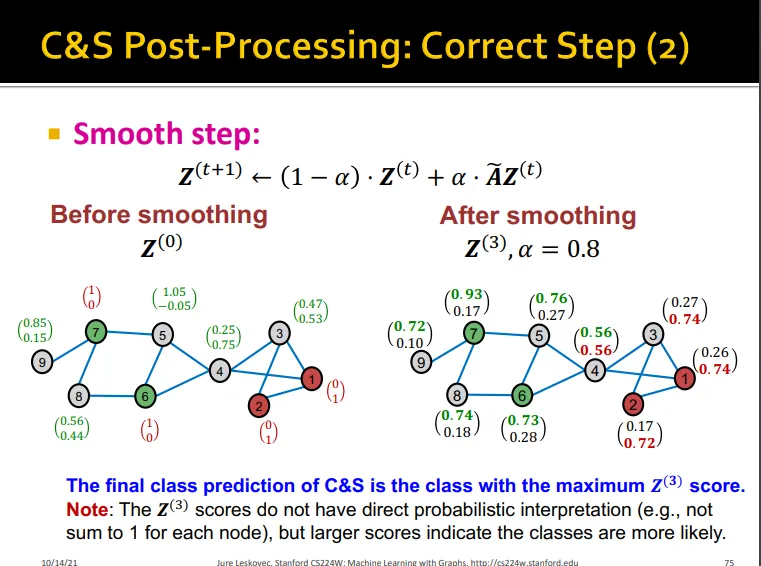
2. Smooth Step
•
Assumption: 노드 값을 share 함
•
hard label 사용하여 다시 diffusion matrix로 전파