•
Link To Paper: https://arxiv.org/pdf/2208.12415.pdf
◦
Music audio를 unconstrained natural music description과 연결
◦
Joint audio-text embedding model과 weakly-associated free-form text annotation으로 구성
◦
Zero-shot fucttionalities를 보임
1. Introduction
•
Music-text joint embedding은 transfer learning, cross-modal retrieval, automatic captionaing 등에 강점을 보임
•
Image에 비해 audio는 caption이 부족함
•
Musical concept을 music audio와 연결 짓는 모델 개발
•
Text prompt로 적절한 장르, 아티스트, 분위기, 구조를 유도
•
인터넷의 4,400만 개 뮤직 비디오에 포함된 텍스트 정보 활용
2. Related Work
2. 1. Audio Representation Learning
•
기존에는 Image Net과 AuidoSet으로 pretrain 된 Audio Spectrogram Transformer(AST)가 state-of-the-art tagging 모델
•
Discriminative training: 같은 recording에 높은 similarity 부여
•
Generative model: Intermediate embedding이 representation으로 의미 있음
•
본 연구에서는 음악과 weakly associated 된 text 활용
2. 2. Cross-modal Contrastive Learning
•
Wrod2Vec으로 generalized 되어있는 embeding구해보려 함
•
AudioSet, ESC-50 데이터 활용됨
•
본 연구에서는 더 넓은 범위의 데이터를 취득하여 transformer based audio and contextual language encoder 구축
2. 3. Music Text Joint Embedding Models
•
Semantic in music을 multi-label classifiation으로 풀려고 함
•
MuLaP은 early fusion을 채택하여 transfer learning application이 제한됨
•
본 연구는 arbitrary music audio에도 natural language interface 제공 가능
3. Proposed Approach
3. 1. Learning Framework
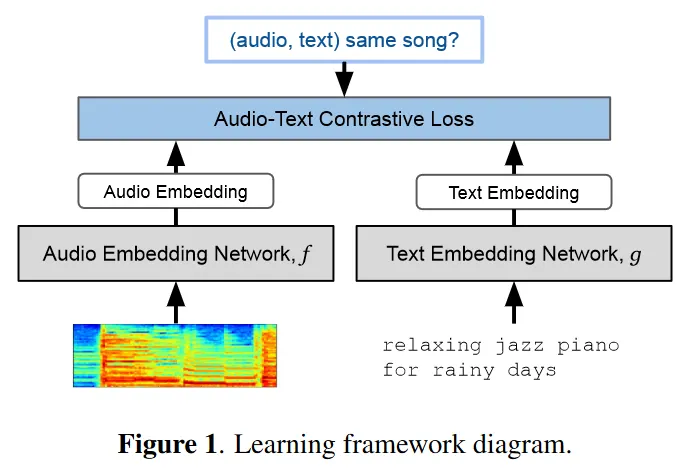
•
Audio embedding network:
◦
F-channel log mel spectrogram
◦
T-frame context windows
•
Text embedding network:
◦
Null-padded text token sequence of length n
•
◦
◦
◦
Mini batch B
•
InfoNCE, NT-Xnet Loss와 같은 contrasitive multi-view coding loss fuction 제시
◦
◦
◦
Hyperparameter
•
Large positive value for target audio-text pairs
•
Small value close to zero for all non-target pairs
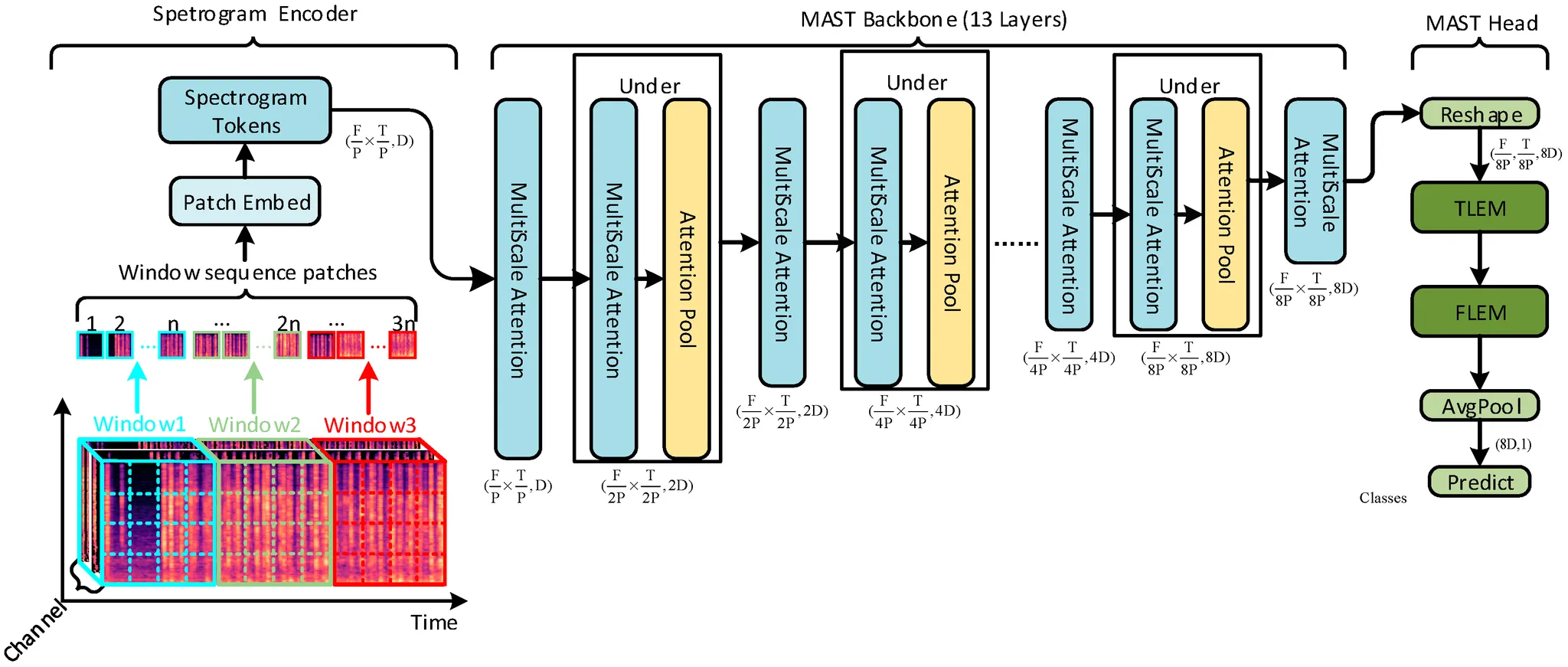
3. 2. Audio Embedding Network
•
ResNet-50 architecture
◦
(F=64) x (T=1000) spectrogram patches
◦
d=128 units
•
Audio Spectrogram Transformer (AST)
◦
12 Transformer blocks
◦
(F=128) x (T=1000) log mel spectogram context windows
3. 3. Text Embedding Network
•
BERT with 12 Transformer blocks
•
String to n=512 tokens
•
Shared audio-text embedding space of d=128
3. 4. Training Dataset Mining
•
From soundtrack of each music video, extract 30-second clip from 30 second mark
•
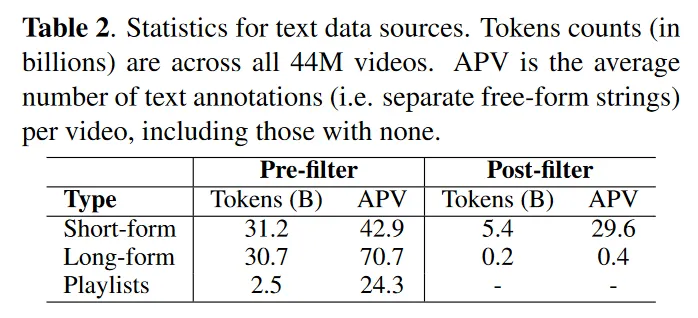
4,400만 개 30-second clips
•
Short-form: video titles and tags
•
Long-form: text including video descriptions and comments
•
Playlits: title of playlists
•
BERT로 text가 음악과 연관이 있는지 체크하도록 함. 이를 활용하여 data cleanse
•
AudioSET(ASET) 데이터도 함께 활용
•
2:2:1:1 for SF:LF:PL:ASET으로 batch 구축
4. Experiments
4. 1. Evaluation Tasks
4. 1. 1. Zero-shot Music Tagging
•
(i) The use of a contextual text encoder로부터 prediction space 학습
•
(ii) The use of cross-modal contrastive learning로부터 language semantics to an audio representation 학습
4. 1. 2. Transfer Learning with Linear Probes
•
MagnaTagATue, AudioSet으로 transfer learning
4. 1. 3. Music Retrieval From Text Queries
•
Playlist titles and descriptions이 더 많은 정보를 담고 있어 이를 바탕으로 음악의 cosine similarity 측정
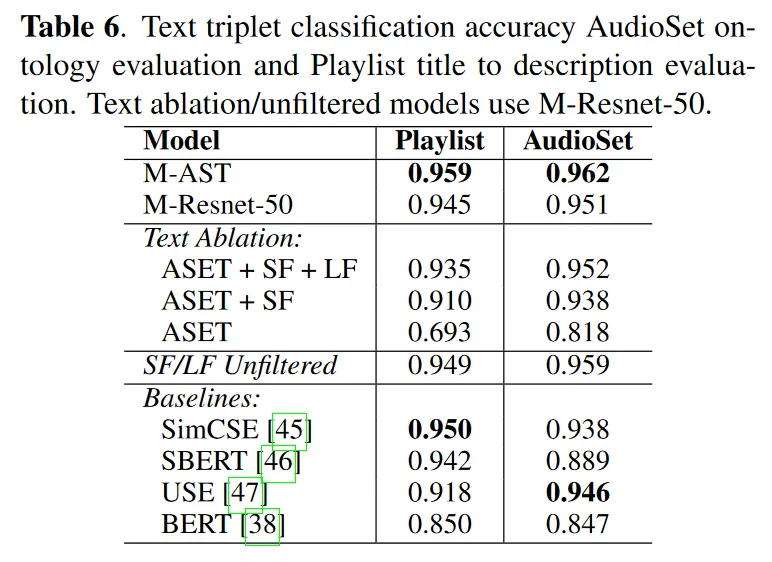
4. 1. 4. Text Triplet Classification
•
3 text strings of (anchor, pos, neg)
•
Considered correct if pos is closer than neg to anchor
4. 2. Results and Discussion
4. 2. 1. Music Tagging
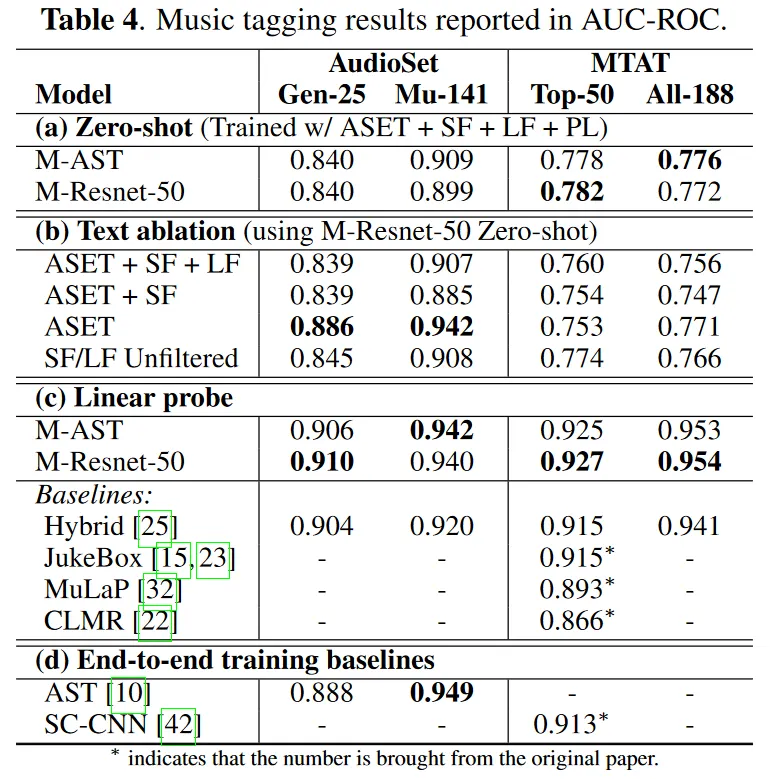
4. 2. 2. Music Retrieval from Text Queries
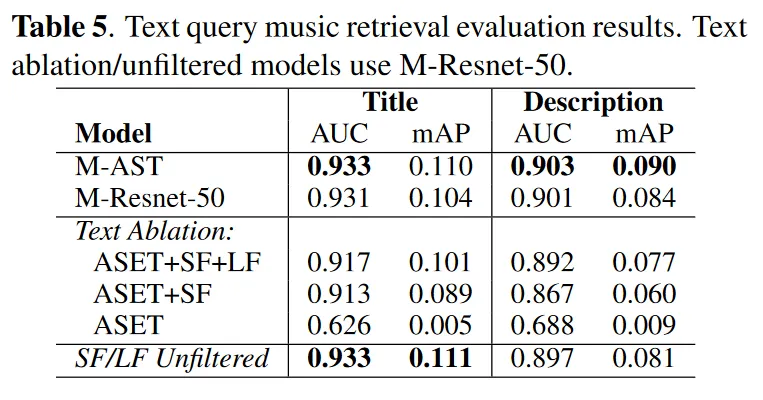
•
Training is surprisingly robust to annotation noise, achieving similar performance using unfiltered training text