

목차
Multi-task learning
•
Models & Training
•
Challenges
•
Case study of real-world multi-task learning
Meta-Learning
•
Problem formulation
•
General recipe of meta-learning algorithms
•
Black-box adaptation approaches
Multi-task Learning
What is a task?
A task: → a data generating distributions
Examples of tasks:
Multi-task classification은 모든 task의 가 같음.
Multi-label learning은 모든 task의 가 같음
** 가 다른 경우는? label이 mixed되어 있거나, 여러 task를 고려할 때.
Model: 가 아닌
각 task를 구분할 수 있는 condition 를 어떻게 적용할 수 있나?
•
각 task를 shared parameter 없이 각각 다른 네트워크에서 학습하거나, 모든 parameter를 share 하거나, 그 중간 어디쯤..
즉 condition 를 선택하는 것은 parameter를 언제, 어떻게 share할지 결정하는 것과 같다!
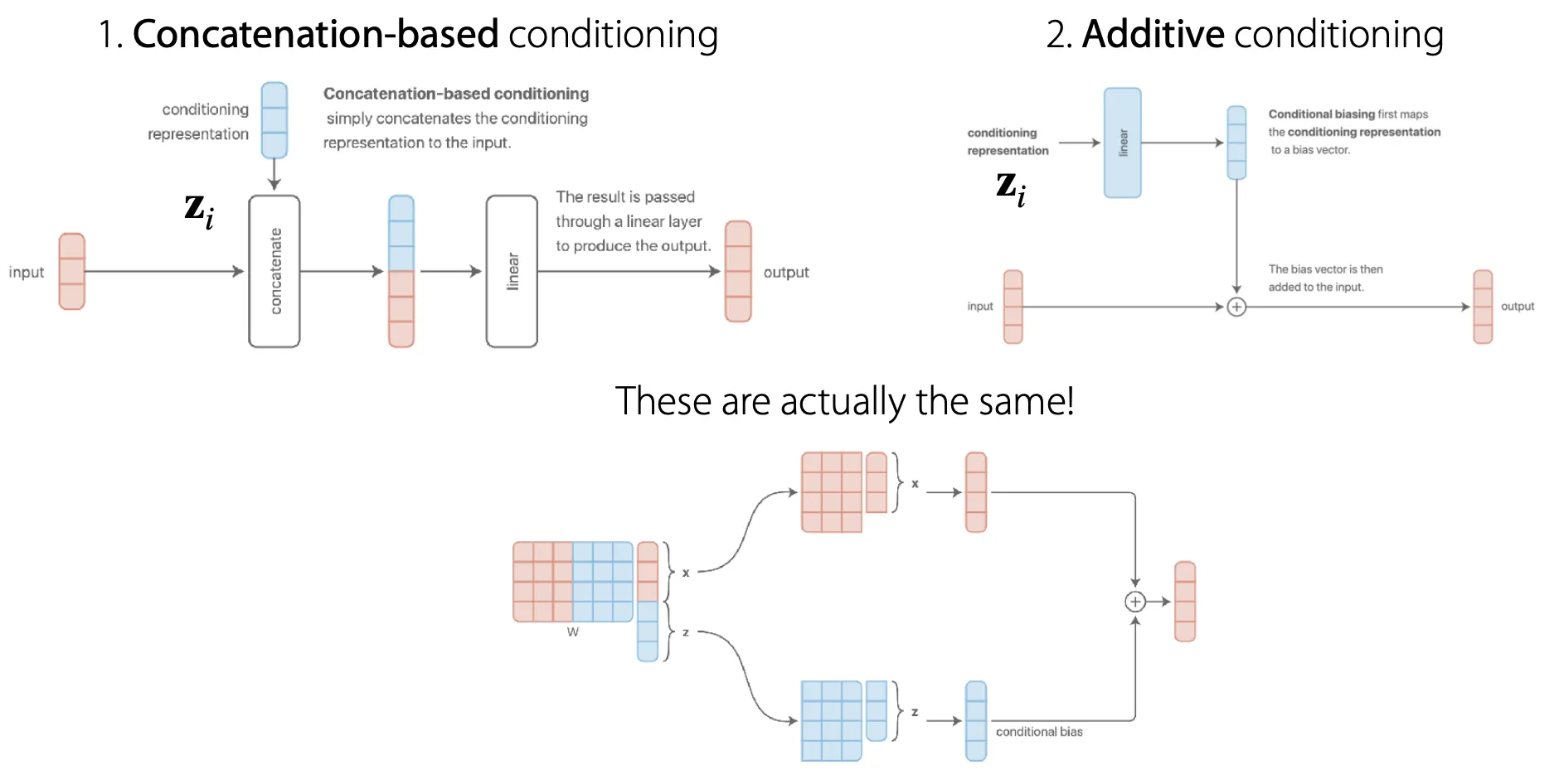
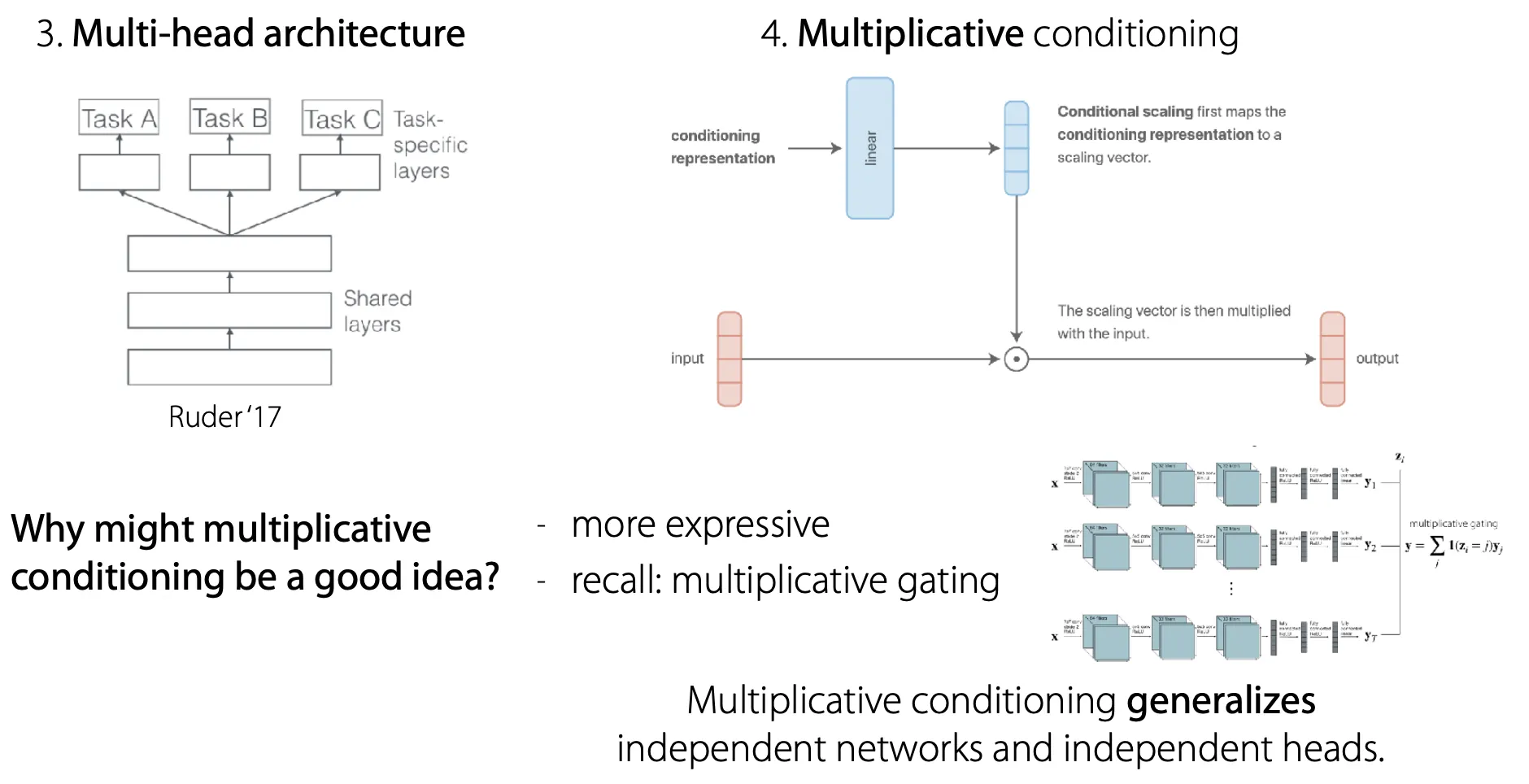
이 중에서는 multiplicative conditioning이 좋은 idea이긴 하지만 다른 neural network tuning과 마찬가지로 task에 따라 좋은게 다르다.
Objective:

Challenges
#1: Negative Transfer
Multi-task에서 함께 weight sharing을 하는 것보다 독립적인 network가 더 좋을 때도 있다.
Why?
Optimization challenges
•
cross-task inference 때문
•
각 task의 학습 속도가 다르기 때문
Limited representational capacity
•
보통 multi-task learning을 위해서는 훨씬 큰 네트워크가 필요
따라서, negative transfer가 예상되면 task에 따라 덜 share해보는 방법 등을 시도해볼 수 있다.
#2: Overfitting
아마도 충분히 share하고 있지 않아 overfitting이 발생하고 있는 것일 수도 있다.
이때는 더 share해본다.
Meta Learning
Two ways to view meta-learning algorithms
Mechanistic view
•
전체 dataset을 읽어서 새로운 data point에 대해 예측할 수 있는 neural network
•
이 neural network를 학습시킬 때 쓰는 dataset은 서로 다른 task를 위한 여러 dataset으로 구성되어 있는 meta-dataset
•
이 관점은 meta-learning algorithm을 구현하는 것을 잘 이해할 수 있게 해준다.
Probabilistic view
•
새로운 task에 대하여 효율적인 학습에 필요한 prior information을 meta-training task들로부터 추출한다.
•
새로운 task를 학습하는 것은 이 prior와 적은 양의 training set을 사용해 가장 최적의 posterior parameter를 찾는 것이다.
•
이 관점은 meta-learning algorithm을 이해하는데 도움을 준다.
Problem definitions
Supervised learning
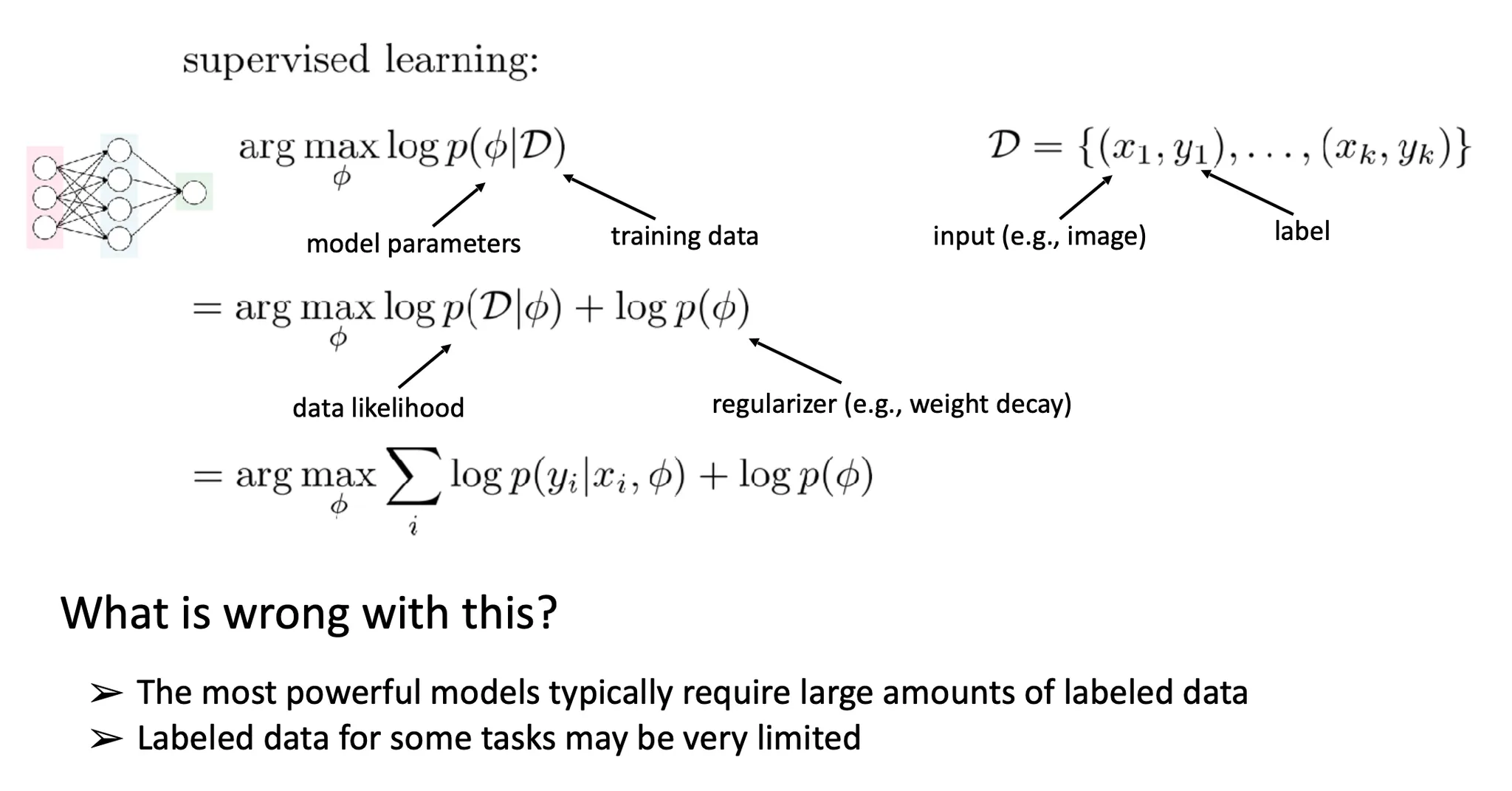
일반적인 supervised learning 상황에서는 위와 같이 likelihood와 regularizer를 분리하여 생각할 수 있다. 하지만 대부분의 모델들은 좋은 성능을 위해 많은 data를 필요로 한다.

직접적인 관련이 있지 않더라도 연관된 data를 추가로 사용할 수 있을까? Task를 구분하여 여러 task를 순차적으로 학습하는 방식으로 사용할 수 있다. 그러나 이 방법은 그 additional data()를 항상 저장하고 있어야 한다는 단점이 있다.

이때, meta-parameter 의 형태로 에 대한 정보를 저장하고자 하는 것이 meta-training이다. 이때 loss function은 위와 같이 분리될 수 있다.
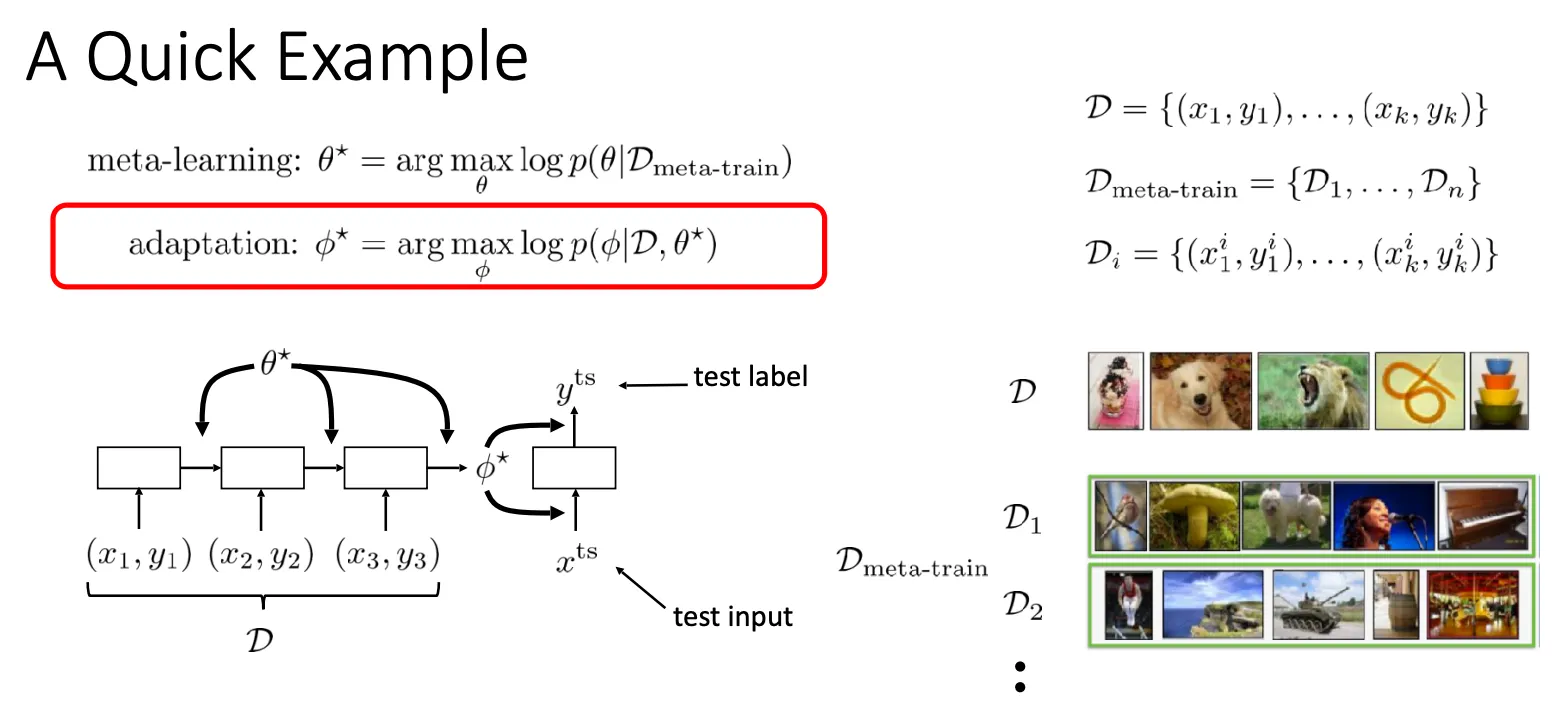
Optimal 를 찾는 것을 meta learning, 각 task에 맞는 를 찾는 것을 adaptation 이라고 생각할 수 있다.
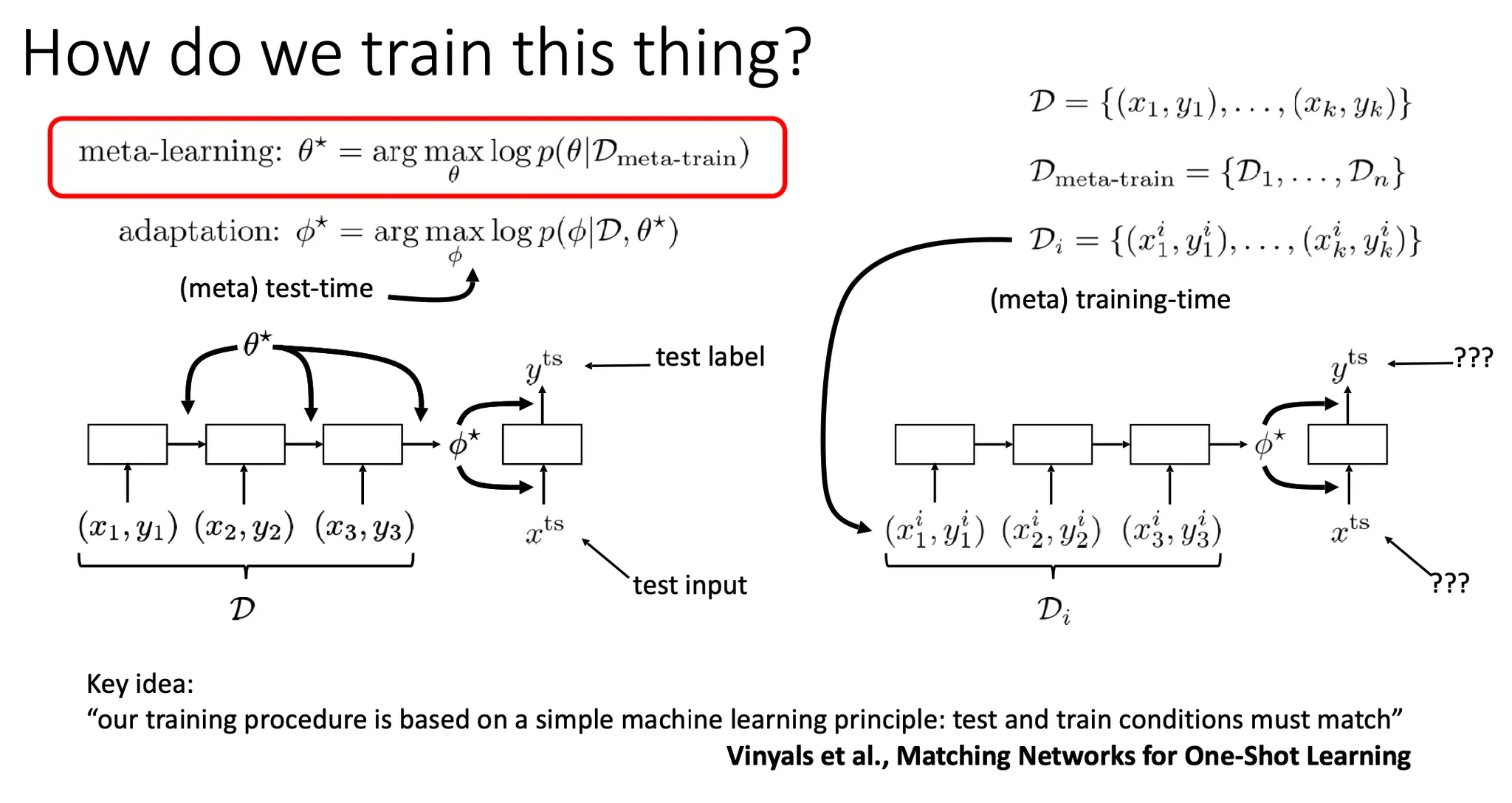
Meta training이 잘 되었는지를 평가하는 test data는 처음에 각 task에 따라 미리 따로 떼어둘 필요가 있다.