

링크
index
문제상황
•
self-supervised 학습, long audio를 high quality로 semantic 일관성 있게 생성하는 모델이 필요하다
◦
self-supervised일 수밖에 없음. audio-text annotation 데이터는 크기가 매우 작다
◦
high quality + long-term consistency 조건이 중요
기여
•
We propose AudioLM, a framework for audio generation that combines semantic and acoustic tokens in a hierarchical fashion to achieve long-term consistency and high quality.
•
We compare the semantic tokens extracted from a pretrained w2v-BERT and the acoustic tokens from SoundStream on a speech dataset, and we show that they complement each other in terms of phonetic discriminability and reconstruction quality.
•
We demonstrate the ability of AudioLM to generate coherent speech in terms of phonetics, syntax and semantics, without relying on textual annotations. Moreover, when conditioned on a prefix (or prompt) of only 3seconds of speech from a speaker not seen during training, AudioLM produces consistent continuations while maintaining the original speaker voice, prosody and recording conditions (e.g., level of reverberation, background noise).
•
We show that AudioLM is also suited for music generation. When training on piano recordings, it generates convincing continuations that are coherent with the prompt in terms of melody, harmony, tone and rhythm.
•
We acknowledge the potential risks associated with the use of generative models that enable speech continuation, and we mitigate these risks by training a classifier that can detect synthetic speech generated by AudioLM with very high accuracy.
방법론
•
SoundStream, w2v-BERT는 pretrained and frozen
Trade-offs of discrete audio representations
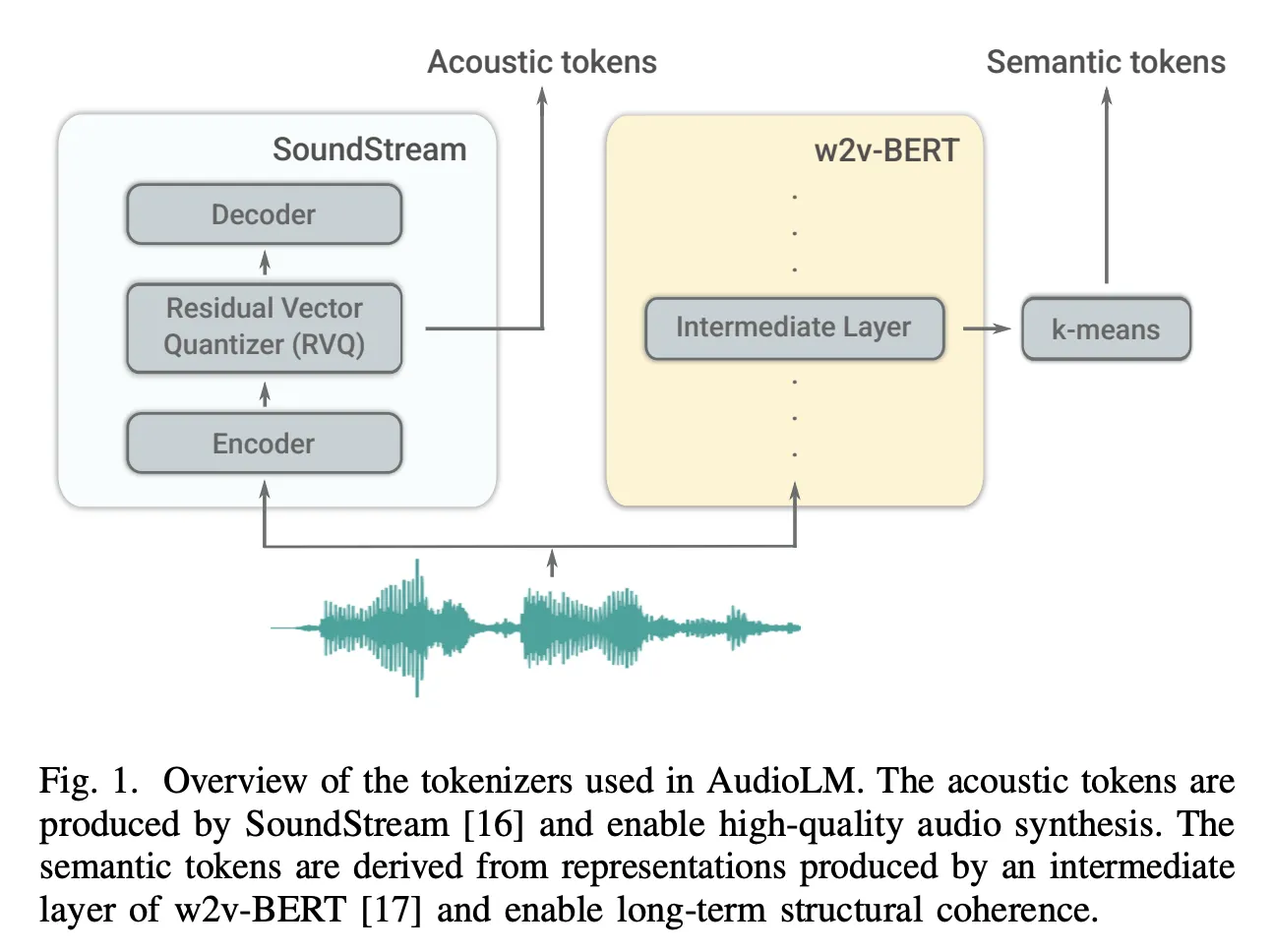
•
long-term dependencies를 capture하는 compact representation을 얻고 싶으면서, 이를 사용해 high-quality audio를 합성하고 싶다 → semantic token, acoustic token 두 개를 사용한다
•
•
Semantic Token
◦
w2v-BERT의 intermediate-layer(7-th layer) output을 사용
◦
w2v-BERT는 large speech corpora로 학습되어, audio waveform을 linguistic features와 잘 mapping함
◦
w2v-BERT의 intermediate output을 K-means clustering해, centroid들을 semantic tokens vocab으로 사용(discretize)
•
두 토큰 타입은 상호보완적일 수 있는가?
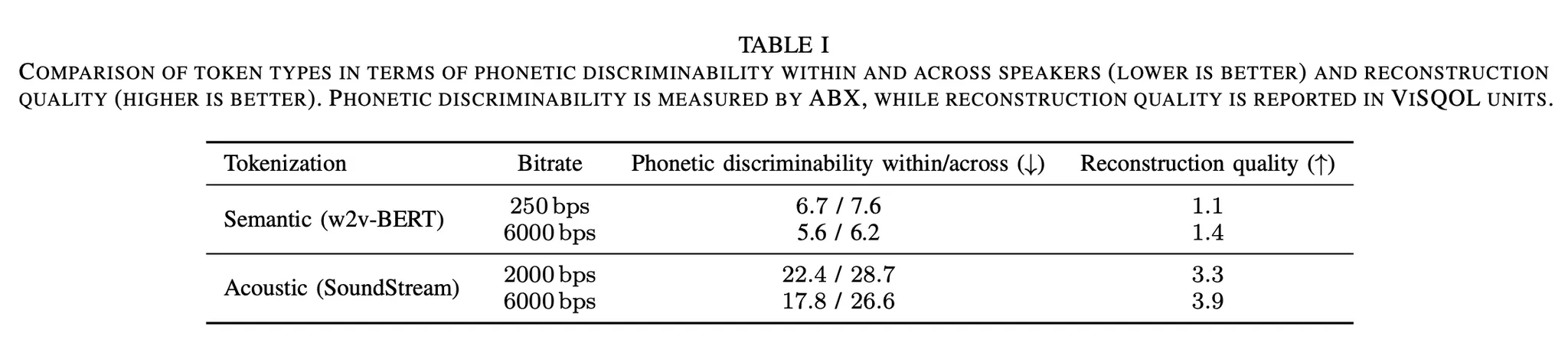
•
Semantic Token은 높은 Phonetic discriminability 성능
•
Acoustic Token은 높은 Reconstruction quality
•
둘은 서로 다른 정보를 담고 있고, 상호보완적이다
•
acoustic token을 사용하여 최종 결과물을 만들되, acoustic token에 semantic token의 정보를 잘 넣어주는 방식으로 combine시킨다.
Hierarchical modeling of semantic and acoustic tokens
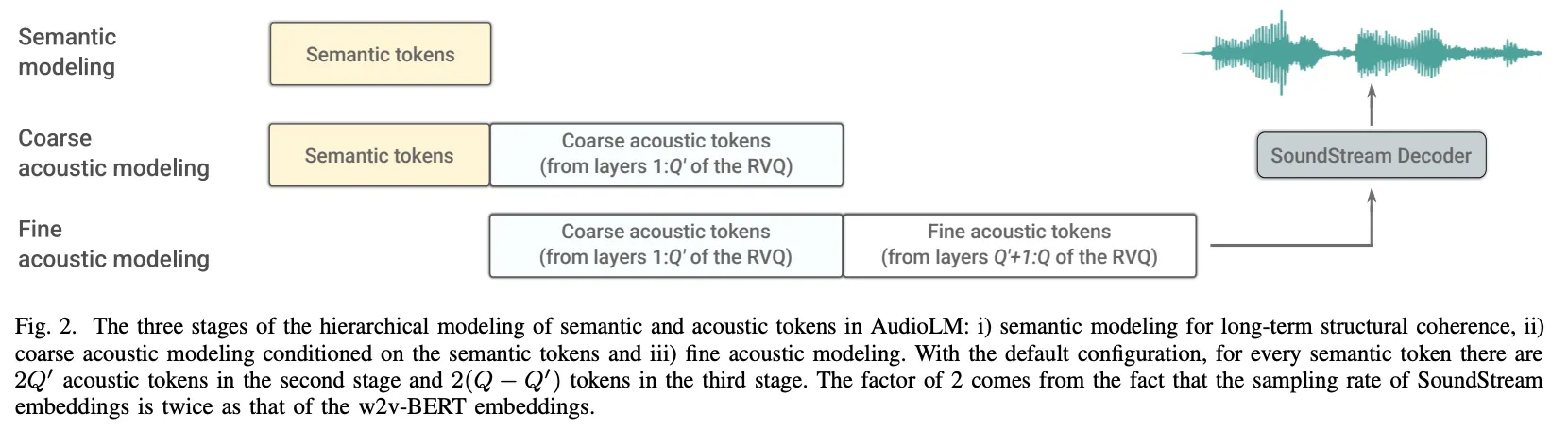
•
Semantic token / acoustic token을 계층적으로 모델링한다
◦
Semantic token은 semantic token들을 통해 모델링
◦
Acoustic token은 semantic / Acoustic token들을 통해 모델링
이유?
•
Semantic modeling
•
w2v-BERT의 output들을 위 autoregressive 방식으로 생성
•
Coarse acoustic modeling
•
SoundStream의 RVQ에서 Q’개의 lower Vectorizer output들을 위 방식으로 생성
•
Fine acoustic modeling
•
SoundStream의 RVQ에서 Q-Q’개의 last Vectorizer output들을 위 방식으로 생성
•
모든 autoregressive process에는 Transformer Decoder가 사용됨(12-layer, 16-head, 1024-dim, *4 ff_factor)
결과
#TODO
관련 연구
High-fidelity neural audio synthesis
•
WaveNet introduced autoregressive classification approach to speech synthesis
◦
variants: WaveRNN, parallel WaveNet
•
Adversarial audio generation is introduced and was a significant paradigm shift.
•
Combining high-quality synthesis systems with differentiable quantization methods allows training end-to-end neural codecs(SoundStream, …)
Self-supervised learning of audio representations
•
Most self-supervised learning approaches rather aim at discovering high-level representations that correlate with coarse, symbolic features such as phonemes, musical notes, class labels.
•
Among these approaches, contrastive training learns representations for which pairs of positive examples are closer to each other than negative pairs.
◦
Positive pairs can be, for example, two segments that are close temporally or two augmented views of the same sequence.
•
Another line of work, inspired by NLP systems pretraining, has explored the discretization of audio signals into a finite vocabulary of tokens to serve as targets for masked language modeling pre-training.
◦
Discretization strategy is critical to the downstream performance.
•
The discriminative nature of these contrastive and predictive objectives, as well as the fact that they require exploiting long-term dependencies, allow learning representations that encode coarse, high-level information about the signal.
◦
주로 speech recognition / audio classification 등의 downstream task에 사용됨
◦
하지만, 오리지널 오디오 시그널의 디테일들을 다 학습하도록 구성되어 있지는 않으므로, 음성 합성에 직접 사용하지는 않음(약간 Language Generation vs Language Understanding의 관계..?)
Generating natural signals with language models.
•
LM-like 모델에서는 self-attention을 주요 모듈로 사용
•
self-attention은 입력 sequence에 대해, 제곱의 속도로 계산 복잡도가 올라감 (O(n^2d)) → natural signals들을 raw form으로 그대로 처리할 수 없음
•
Solution: work with mappings of the natural signals to a compact, discrete representation space.