
링크
index
Problems
•
Text → 음성 합성의 어려움
◦
high-quality + long-term coherence 유지의 어려움(AudioLM)
◦
scarcity of paired audio-text data
▪
 img: massive datasets contributed significantly to the remarkable image generation quality
img: massive datasets contributed significantly to the remarkable image generation quality◦
audio에 특화된 문제점들
1.
It is not straightforward to unambiguously capture with just a few words the salient characteristics of either acoustic scenes (e.g., the sounds heard in a train station or in a forest) or music (e.g., the melody, the rhythm, the timbre of vocals and the many instruments used in accompaniment).
2.
Audio is structured along a temporal dimension which makes sequence-wide captions a much weaker level of annotation than an image caption.
Contributions
1.
We introduce MusicLM, a generative model that produces high-quality music at 24 kHz which is consistent over several minutes while being faithful to a text conditioning signal.
2.
We extend our method to other conditioning signals, such as a melody that is then synthesized according to the text prompt. Furthermore, we demonstrate long and coherent music generation of up to 5-minute long clips.
3.
We release the first evaluation dataset collected specifically for the task of text-to-music generation: MusicCaps is a hand-curated, high-quality dataset of 5.5k music-text pairs prepared by musicians.
Methods
MusicLM builds on top of AudioLM with three important additional contributions
1.
We condition the generation process on a descriptive text
2.
We show that the conditioning can be extended to other signals such as melody
3.
We model a large variety of long music sequences beyond piano music (from drum’n’bass over jazz to classical music)
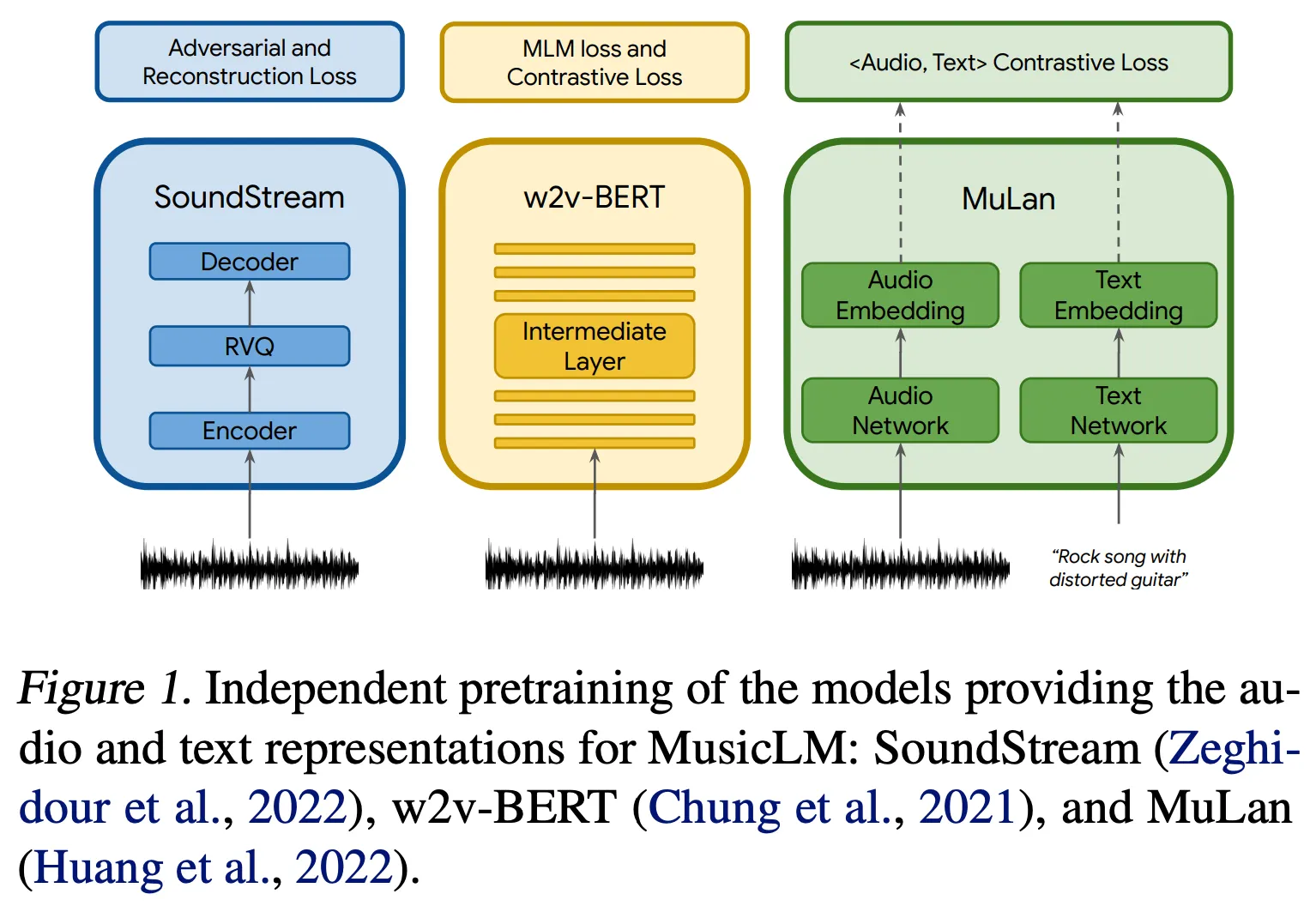
Representation and Tokenization of Audio and Text
•
SoundStream으로 Acoustic Token 생성
•
w2v-BERT로 Semantic Token 생성
•
MuLan Embedding으로 Conditioning
◦
Train: w/ only music, MuLan Audio Embedding 사용
◦
Inference: 유저의 입력 텍스트들을 MuLan Text Embedding 사용해 임베딩
•
SoundStream
◦
24kHZ audio에 stride 480 = 50Hz embeddings
◦
RVQ with 12-quantizers, each w/ vocab size 1024
◦
bitrate = 50 * 12 * 10 = 6000bps, 600 acoustic tokens for every second of audio
•
w2v-BERT
◦
Similar to AudioLM, extract embeddings from the 7th layer and quantize them using the centroids of a learned k-means over the embeddings. We use 1024 clusters and a sampling rate of 25 Hz, resulting in 25 semantic tokens for every second of audio.
•
MuLan
◦
MuLan이 최대 10초의 음성밖에 처리 못하므로, 1초씩 stride하여 오디오를 입력하고 전체 임베딩을 평균함
◦
이후, RVQ(12 vectorizers, 1024 vocab size)로 quantize하여 12개의 MuLan Audio Token을 생성함
◦
Inference 시에는 Text 임베딩에 대해 동일한 RVQ를 적용함
Hierarchical Modeling of Audio Representations
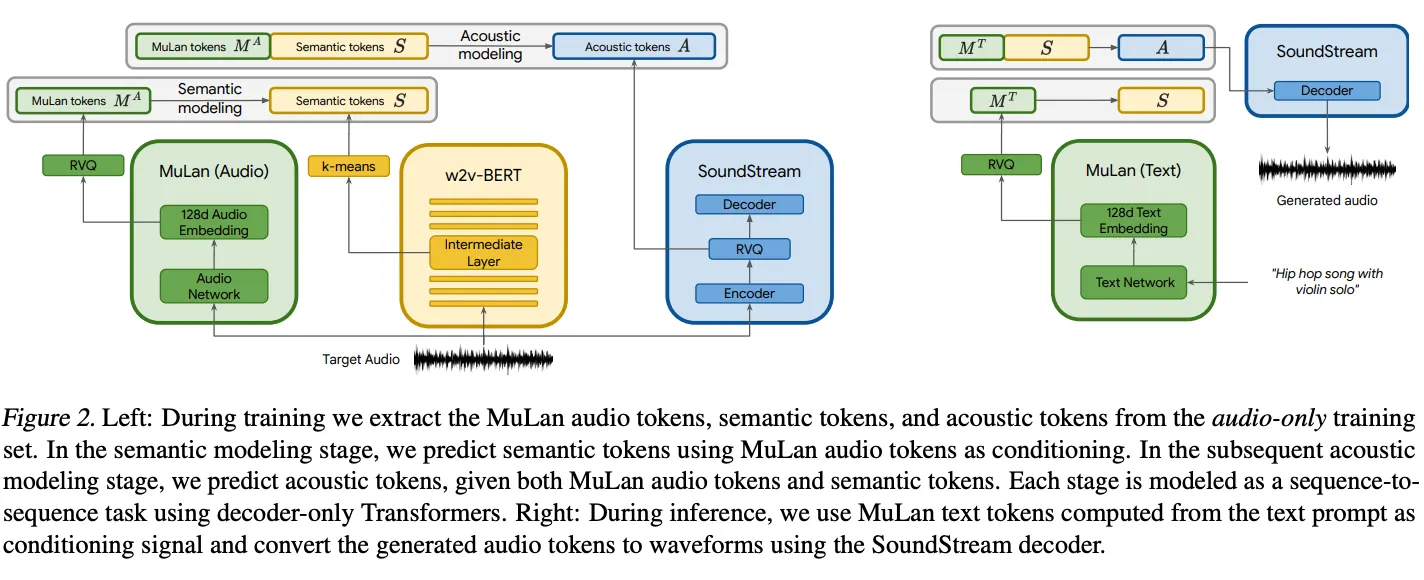
•
각 stage는 서로 다른 Transformer decoder로 autoregressively modeling됨
S: semantic token
M: mulan token
A: Acoustic token
1.
semantic modeling stage: MuLan embedding 기반으로 semantic token sequence 생성
2.
acoustic modeling stage: MuLan embedding, semantic token sequence 기반으로 acoustic token sequence 생성
•
위 수식은 acoustic token을 시간당 하나씩 생성하는 것으로 되어 있지만, 실제로는 아님. AudioLM의 detail을 따름.
•
각 stage들의 transformer decoder details
◦
24 layers, 16 attn heads, 1024 dim, x4 ff factor
Results
Train
•
SoundStream, w2v-BERT: Free Music Archive(FMA) Dataset으로 학습
•
MuLan: pretrained
•
세 모듈이 각각 학습되고 freeze된 후, autoregressive part(transformer decoder)이 학습됨
◦
5M audio clips, 280k hours of music at 24kHz
•
semantic stage, acoustic stage의 입력으로 input audio의 30초, 10초짜리 랜덤 크롭을 사용
Evaluation
•
MusicCaps 데이터셋을 직접 모음
◦
5.5k music clips from AudioSet - each paired with corresponding text descriptions in engish(10 professional musicians wrote)
◦
for each 10-second music clip,
▪
free-text caption consisting of four sentences on average
▪
list of music aspects(genre, mood, tempo, singer voices, instrumentation, dissonances, rhythm…)
Results
•
Compare with baselines
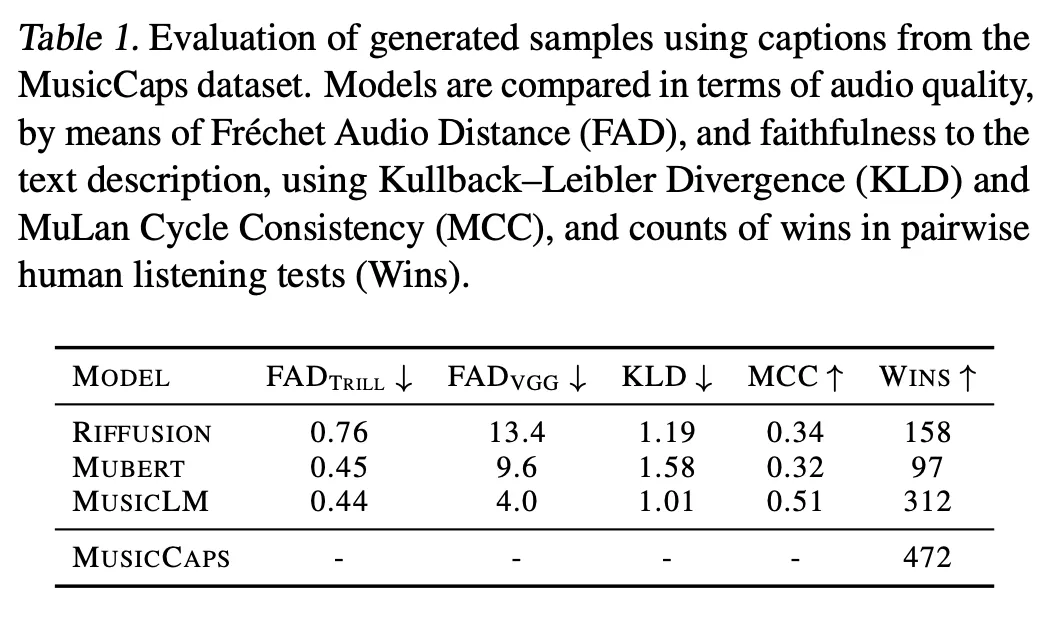
•
FAD: audio quality를 평가하는 metric, lower is better
◦
Trill, VGG: 각각 speech 퀄리티, non-speech 퀄리티를 중심으로 평가한다고 함)
•
KLD: audio 입력과 text 입력에 대한 classifier의 출력의 distribution 비교(lower: audio ~ text의 acoustic align이 잘 맞는다)
•
MCC: MuLan Text embedding과 생성된 음악의 MuLan Embedding의 avg cosine similarity. higher: audio ~ text 유사도 높다
•
Wins: human judgement(질적 평가)
•
Importance of semantic tokens
◦
semantic token modeling을 건너뛰고, mulan token에서 바로 acoustic token 예측하도록 함
◦
FAD_trill = 0.42 // FAD_VGG = 4.0 → 큰 변화 없음
◦
KLD = 1.05 // MCC = 0.49 → 하락
◦
semantic token은 text와의 align에 관여한다
•
Information represented by audio tokens
◦
실험 1) MuLan token, semantic token 모두 고정하고 acoustic modeling만 여러 번 해 봄
▪
In this case, by listening to the generated music, it is possible to observe that the samples are diverse, yet they tend to share the same genre, rhythmical properties (e.g., drums), and part of the main melody. They differ in terms of specific acoustic properties (e.g., level of reverb, distortion) and, in some cases, different instruments with a similar pitch range can be synthesized in different examples.
◦
실험 2) MuLan token만 고정하고, semantic modeling, acoustic modeling을 여러 번 해 봄
▪
In this case, we observe a much higher level of diversity in terms of melodies and rhythmic properties, still coherent with the text description.
Extensions
1.
Melody Conditioning
•
We create a synthetic dataset composed of audio pairs with matching melodies but different acoustics.
◦
커버 음악, 악기 연주, 보컬 버전 등 동일한 음악의 다른 버전을 수집
◦
추가로, 사람들의 허밍, 노래하는 데이터를 수집
•
We then train a joint embedding model such that when two audio clips contain the same
melody, the corresponding embeddings are close to each other.
•
To extract the melody conditioning for MusicLM, we quantize the melody embeddings with RVQ, and concatenate the resulting token sequences with the MuLan audio tokens.
•
During inference, we compute melody tokens from the input audio clip and concatenate them with the MuLan text tokens.
•
concat된 입력을 조건으로 하여 semantic / acoustic stage 진행됨
2.
Long generation and story mode
•
MusicLM의 semantic modeling은 30초밖에 입력으로 처리할 수 없어서, 15초를 stride로 하여, 다음 15초에 대해서는 기존 text condition과 이전 15초 음성을 함께 입력으로 주어 생성 → longer generation 가능
•
매 15초간, 새로운 text condition 과 이전 15초 음성을 주어 생성하게 만들면, 시간에 따라 달라지는 text input에 따른 음성을 생성할 수 있다 → story mode