

Scale up GNNs to large graphs!
•
보통 large data에서는 mini-batch에서 SGD 수행

•
GNN에서는 미니 배치 내에서 노드를 샘플링하면 노드가 서로 떨어져 있게 됨

•
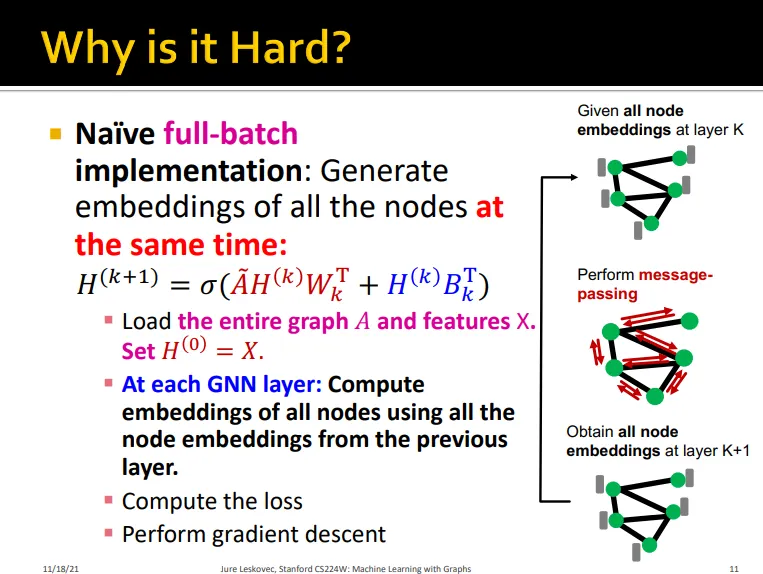
full-batch로 학습?
•
GPU 메모리상 불가

본 강에서는
•
subgraph를 이용한 학습
◦
Neighbor Sampling
◦
Cluster-GCN
•
feature preprocessing으로 GCN을 단순화한 학습
◦
Simplified GCN
을 다룸.

GraphSAGE Neighbor Sampling
•
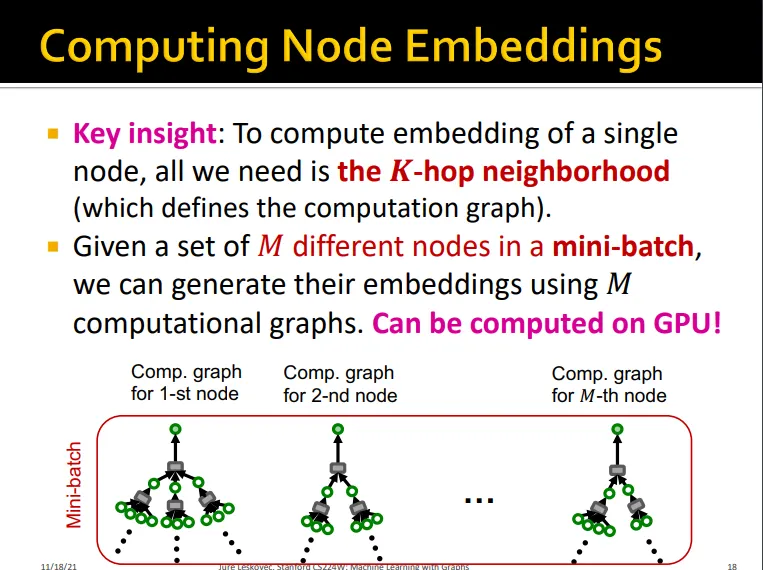
노드 하나를 학습시키는데 필요한건 K-hop의 neighborhood임
•
그럼 M개의 mini-batch에서 우리는 M개의 computational graphs만 있으면 됨
•
그래서 M개의 노드에 대해서 위 방법으로 averaged loss를 구함

•
Issue 1
◦
노드마다 K-hop neighborhood를 모두 구해서 computation graph에 넣어야 함(한 노드마다 계산할 정보가 너무 많음)

•
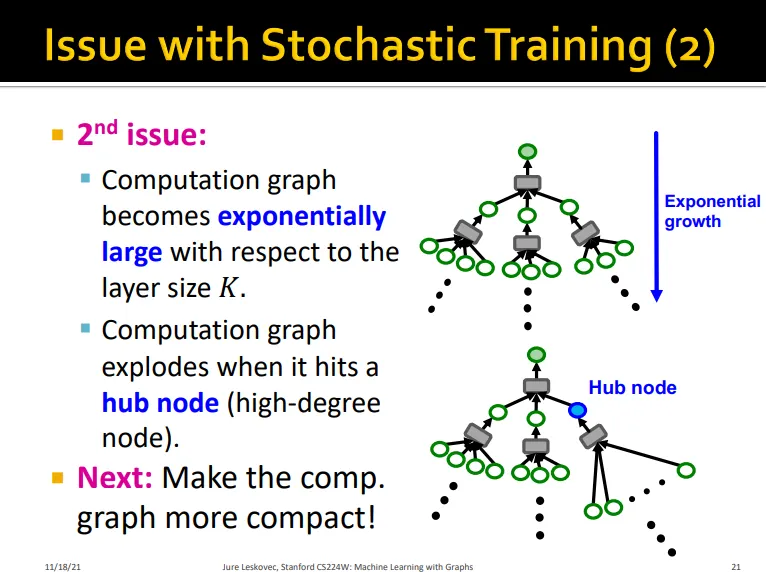
Issue 2
◦
layer num K가 커지면 computation graph가 기하급수적으로 커짐
◦
hub node를 건드리면 폭발함
→ 보다 compact한 computation graph를 만들 필요가 있음
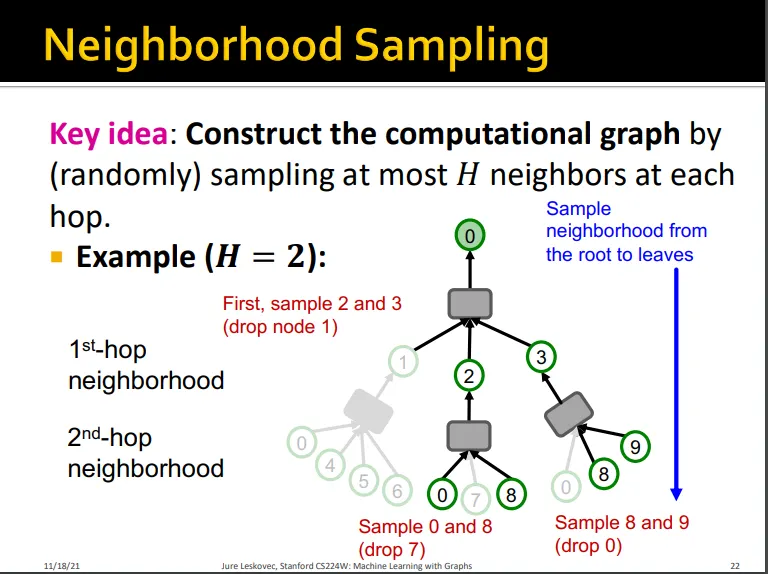
Neighborhood Sampling
•
각 hop마다 이웃 노드를 샘플링함
•
computational graph를 pruning
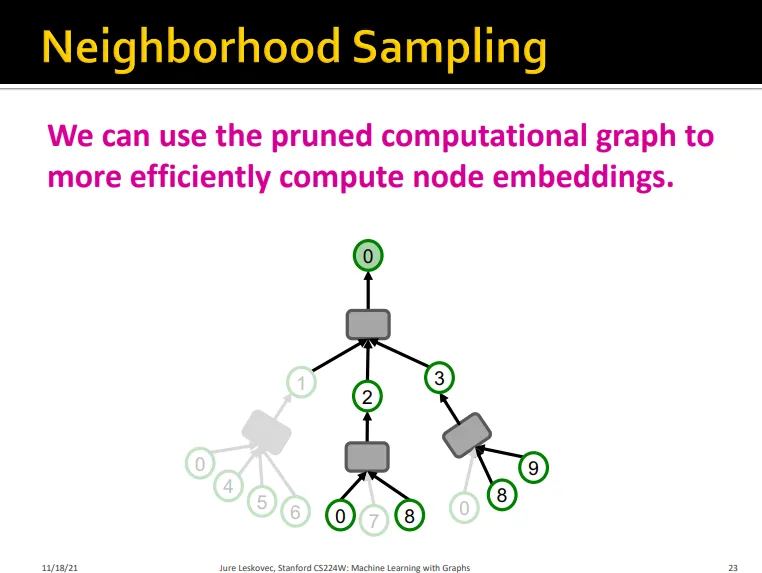
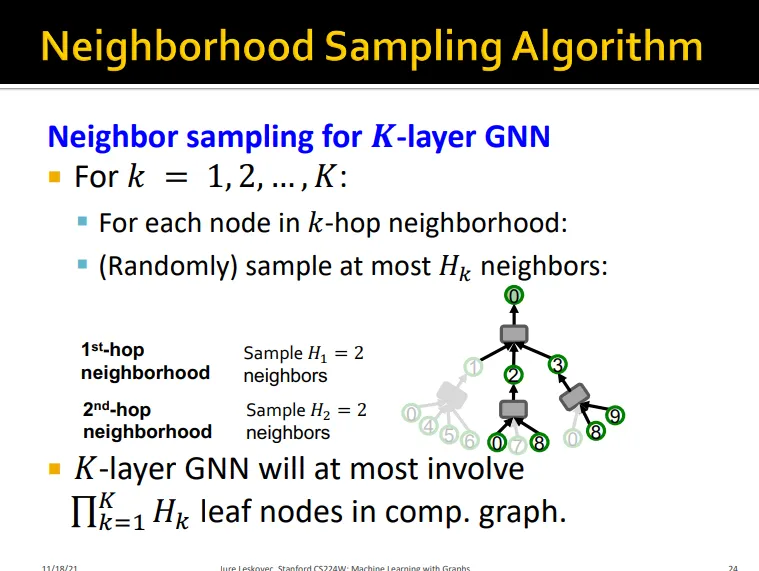
•
Remark
◦
H가 작으면 더 효율적이나 neighbor aggregation의 variance 커짐
→ unstable training
◦
샘플링하더라도 layer num K에 따라서 computation graph는 여전히 지수함수적으로 증가

•
Sampling을 어떻게 할지의 문제
◦
random sampling
▪
빠르지만 optimal은 아닐 수 있음
◦
random walk with restarts
▪
중요한 노드를 샘플링하기 위한 전략
▪
random walk을 통해 neighbor scoring
▪
실제로 꽤 잘 기능함
▪
PinSAGE?

•
요약
◦
neighbor sampling은 pruning한 computational graph를 만듦
◦
하지만 layer가 많을 경우 이 또한 여전히 사이즈가 큼

Cluster-GCN
•
neighbor sampling에서의 이슈를 다시 살펴보면,
◦
mini-batch 내에서 서로 이웃을 많이 공유하면 서로 computation graph 일부를 공유해서 연산히 redundant해짐
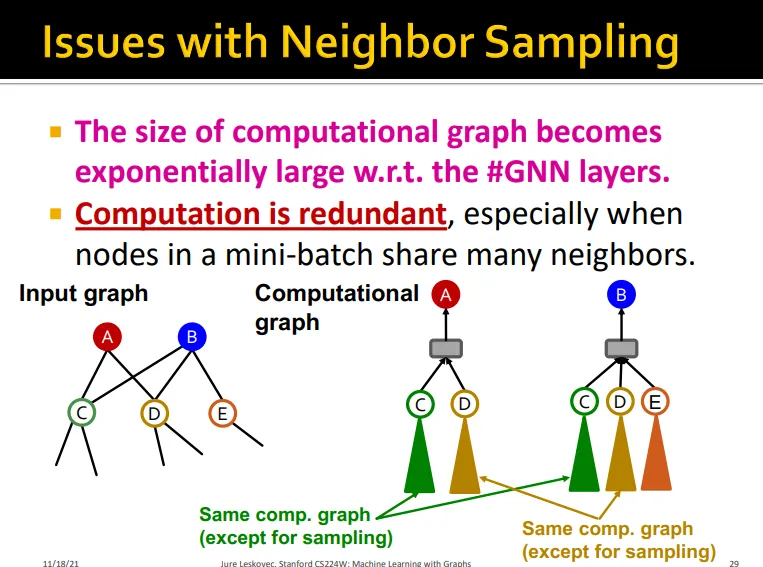
•
Full-batch로 학습할 때는 같은 embedding을 여러번 반복할 필요가 없었음
◦
그럼 subgraph를 sampling하고 subgraph를 full-batch로 학습하자!

•
그럼 어떤 subgraph가 gnn 학습에 좋은 그래프인가?
◦
gnn은 node embedding을 edge를 통해서 함
◦
따라서 edge connectivity를 original graph만큼 잘 살린 그래프가 좋음

•
원래 그래프 구조를 잘 살린 왼쪽 그래프가 good

•
실제 그래프는 커뮤니티 구조를 가져서 작은 여러개의 커뮤니티들로 쪼갤 수 있음

Vanilla Cluster-GCN
•
두 단계로 나뉨
◦
Pre-processing
▪
하나의 large graph를 여러 개의 subgraph로 나눔
◦
Mini-batch training
▪
하나의 subgraph에 대해서 message passing 수행
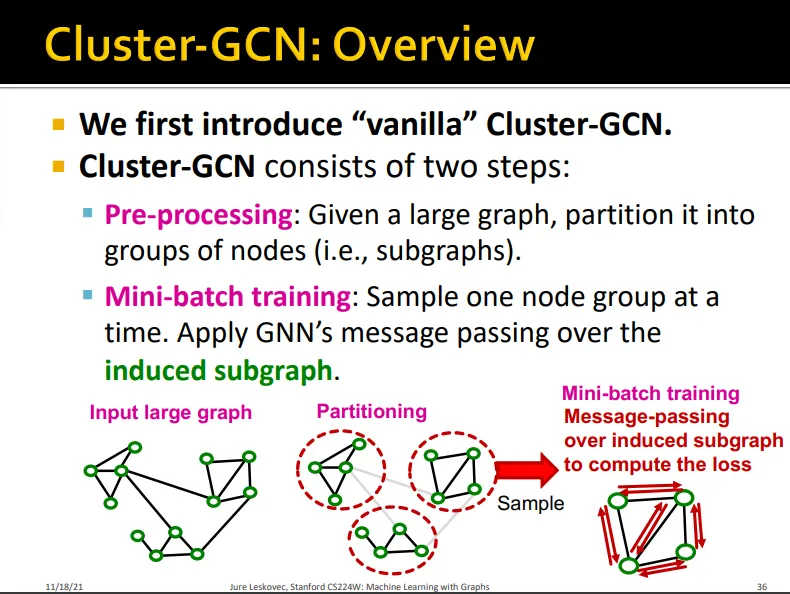
•
C 개의 group으로 나눔
•
이때 그룹 사이의 엣지는 포함하지 않음

•
subgraph 에 대해서 layer-wise node update
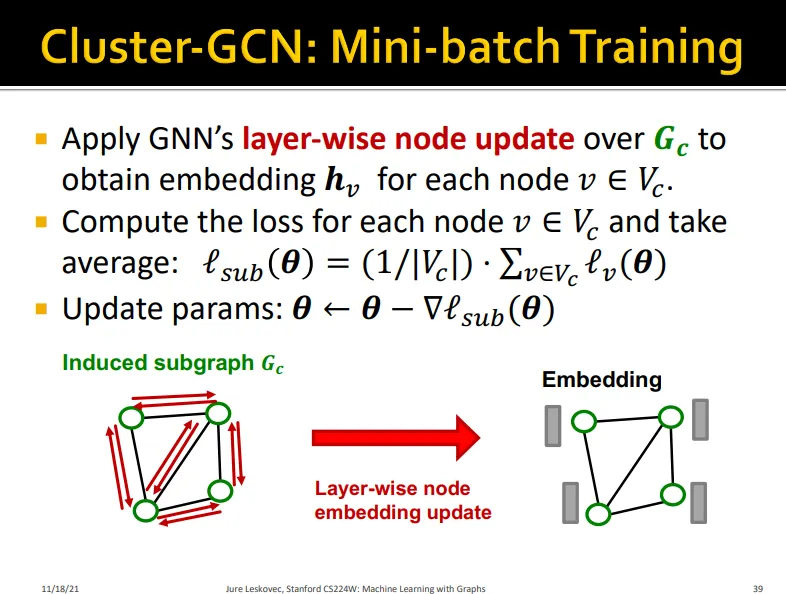
•
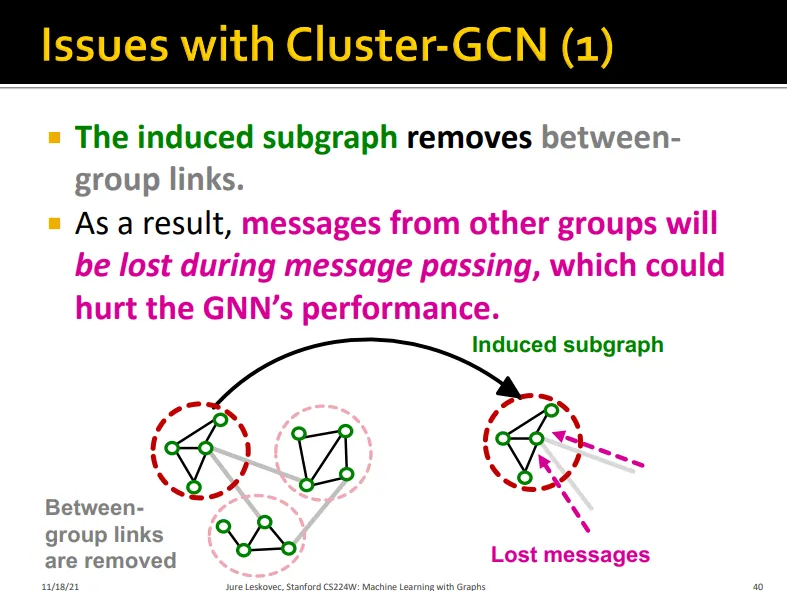
Issue 1
◦
group link를 삭제하기 때문에 그룹 간의 정보는 message passing할 때 사라짐. 성능 저해..
•
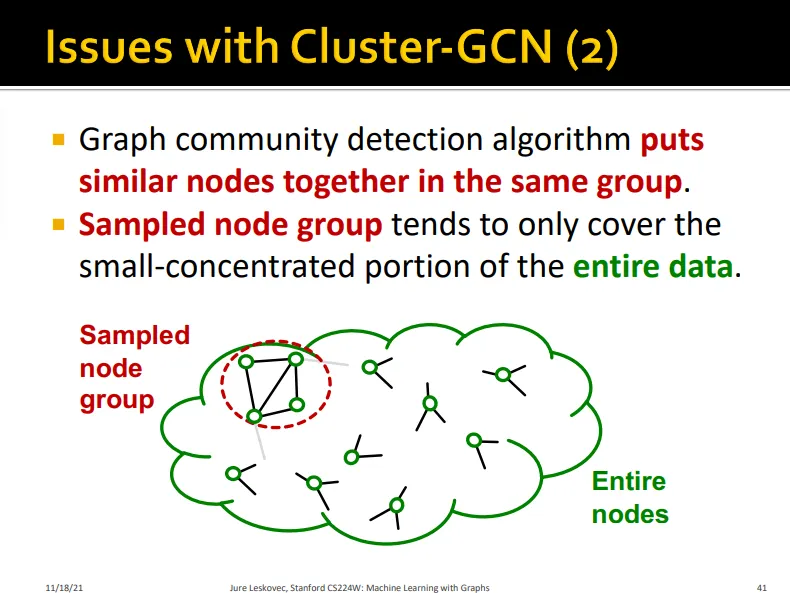
Issue 2
◦
graph community detection algorithm은 비슷한 노드들을 하나의 그룹에 넣음
◦
이러한 노드 그룹은 전체 데이터의 일부만 설명함
•
Issue 3
◦
하나의 그룹은 그래프 전체를 표현하기에 충분히 다양하지 않음
◦
노드 그룹이 달라질 때마다 변동성이 커짐
◦
수렴이 느리게 나타남

Advanced Cluster-GCN
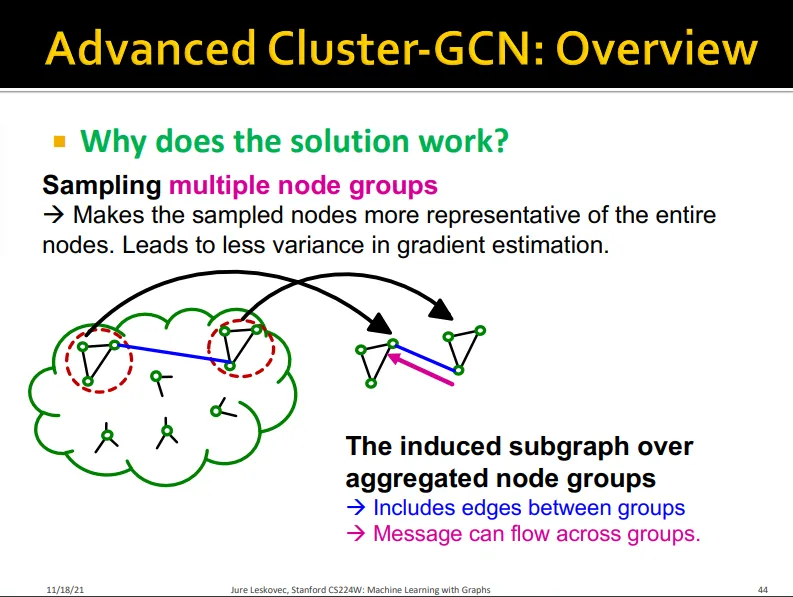
•
그래프를 좀 더 작게 쪼개고 mini-batch에서 이를 합치자

•
여러 노드 그룹을 쓰기 때문에 전체 그래프를 보다 잘 표현함
•
그룹 간의 링크가 있어, message가 그룹 사이에도 흐를 수 있음
•
Pre-processing
◦
vanilla와 같이 subgraph으로 나누되 더 작게 나눠서 나중에 aggregate 됐을 때 사이즈가 너무 커지지 않게 해야 함

•
Mini-batch training
◦
subgraph 중 random으로 일부 샘플링
◦
속한 node들을 전부 aggregate해서 하나의 subgraph으로 만듦
◦
이때 between-group edge를 포함

•
Time complexity를 neighbor sampling과 비교해보면,
◦
neighbor sampling은

•
Cluster-GCN은

•
이웃 노드 절반만 샘플링해서 라고 할 때,
◦
Cluster-GCN은 , neighbor sampling은 의 time complexity
◦
Cluster-GCN은 K에 대한 linear한 dependency를 가짐

•
Summary
◦
Cluster-GCN은 전체 노드를 작은 노드 그룹으로 나누고 이를 mini-batch에서 합쳐 학습함
◦
layer-wise node embedding을 하기 때문에 layer 수가 많을 때 특히 neighbor sampling 보다 효율적임
◦
하지만 cross-community edge를 상실해 학습이 편향된다는 단점이 있음

Simplifying GNN
•
앞서, non-linear activation을 없앤 LightGCN의 성능 저하가 크지 않은 것을 확인하였음
•
Simplified GCN은 모델 구조 상 매우 scalable함

•
LightGCN는 ReLU non-linearity가 없음

•
LightGCN은 self-loop이 있고
•
Input embedding 가 학습되는 feature 라기 보다 given feature에 가까움
◦
는 한번만 계산되면 됨 (전처리 과정에 가까움)

•
LightGCN은 linear model 학습시키는게 GCN과 비슷한 성능을 낸다는 것을 보여줌

•
다만 non-linearity가 없어서 표현력이 낮음

•
하지만 semi-supervised node classification에서 simplified GCN은 original GNN과 거의 비슷한 성능을 보임

•
많은 node classification에서는 homophily structure가 관찰됨
◦
연결된 노드들은 비슷한 라벨을 가질 가능성이 큼

•
simplified GCN은 neighbor node feature를 반복적으로 평균내는 것이기 때문에, 연결되어 있는 노드들은 비슷한 pre-processed feature를 갖게 됨

•
그래서 연결되어 있는 노드들은 모델에 의해 같은 라벨로 예측되게 됨
•
Simplified GCN은 graph homophily를 잘 반영하는 모델인 것
→ 많은 node classification dataset에 적합
