


개요
•
LLaMA가 다양한 벤치마크에서 좋은 성능 보여줬지만, ChatGPT처럼 일반적인 지시나 질문에 자연스럽게 답변하지는 못함
•
ChatGPT 모델은 Instruction-following 데이터로 finetuning 했기 때문에 사용자 의도에 맞게 답변 잘함
•
Alpaca : LLaMA를 instruction-following 데이터로 finetuning 한 모델
학습 방법
•
Self-Instruct
◦
대량의 instruction 데이터셋 생성하기 위해 사람이 아닌 LLM을 활용
◦
최초 instruction seed는 사람이 작성하고, 이를 이용해 LLM이 새로운 지시(instruction)와 해당 입력-출력 인스턴스 생성
◦
LLM이 생성한 결과 필터링해 task pool에 다시 추가
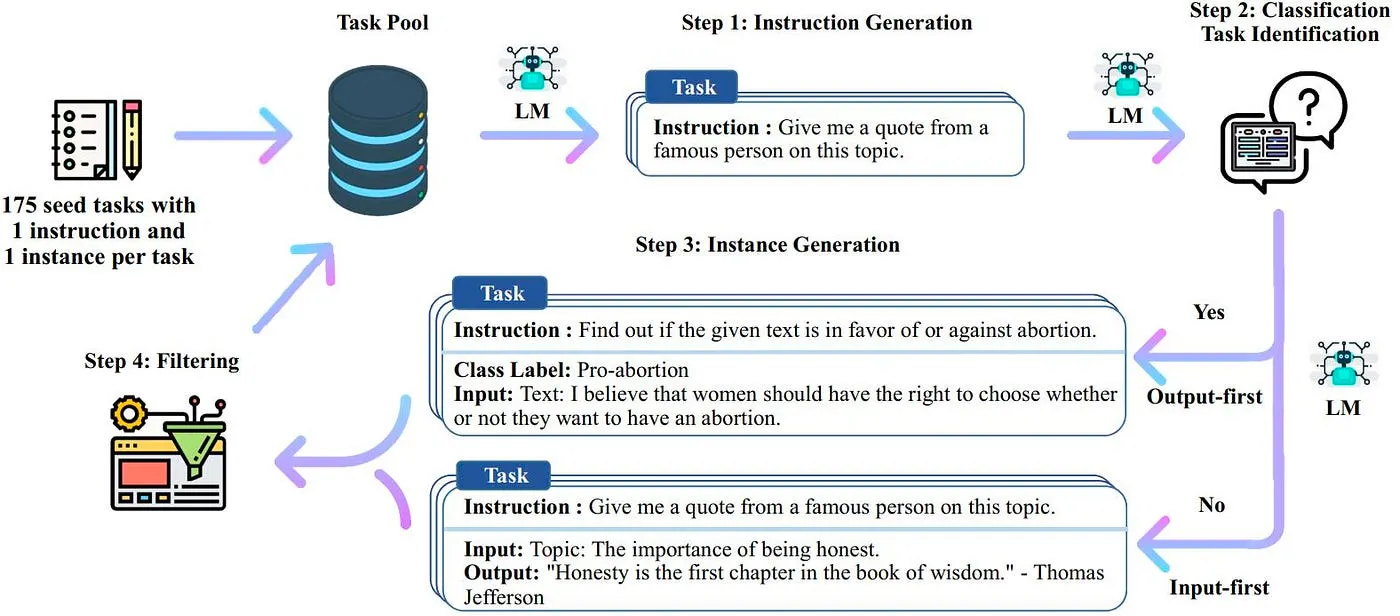
•
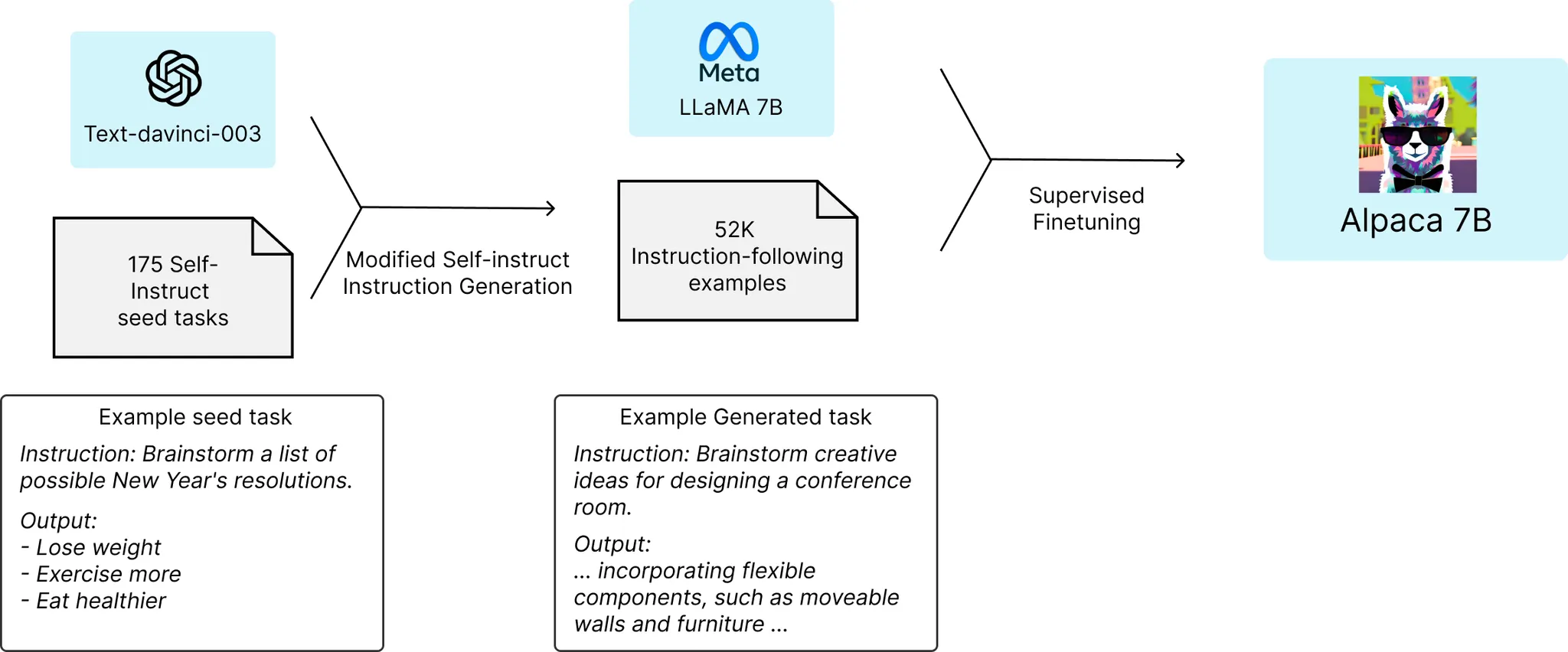
Alpaca
◦
Step 1
▪
Self-struct seed로 사람이 작성한 instruction-output 쌍 준비
▪
GPT-3(text-davinci-003)의 프롬프트로 self-instruct seed 입력해 추가 instruct data(52K) 생성
▪
OpenAI API 사용 비용 : $500 이하
◦
Step 2
▪
52K instruction-following samples로 LLaMA 모델을 Supervised finetuning해 Alapca 모델 생성
▪
FSDP(Fully sharded Data Parallel)과 Mixed Precision 같은 기술 이용해 8개의 A100에서 3시간 동안 finetuning
▪
이때 사용한 cloud 요금은 $100 미만
→ Google Cloud 기준 A100 GPU (80GB) 1대당 $3.93/hour 요금제(Iowa(us-central1))를 가정하였을 때, $3.93/hour * GPU 8대 * 3 hours = $94.32가 나오니 실제 타당한 금액
평가
•
GPT-3.5(text-davinci-003)와 Alpaca-7B간 blind 비교를 실시하였을 때, Alpaca가 90대 89로 근소하게 이김
•
Self-instruct와 LLaMA-7B를 이용하여 불과 $600로 text-davinci-003와 동등한 성능의 foundation model 만들어 냄
의의
•
LLaMA, polyglot과 같은 사전학습된 모델과 Self-Instrcut method를 활용했을 때 저렴한 비용으로 뛰어난 성능의 Instruction-following model를 만들 수 있음
◦
GPT-3.5에 적용된 RLHF는 Supervised fine-tuning을 위해 인간 Labeler가 수동으로 데이터셋을 만들어야 했음
◦
Alpaca의 접근 방식은 instruction-following model을 만드는데 인간의 작업을 획기적으로 줄여 foundation model을 만드는 비용을 낮춤
•
미래에 Foundation Model에 대한 접근권은 일부 기업들이 독점할 것으로 보이나, 이에 대한 반작용으로 리눅스와 같이 오픈 소스화된 Foundation Model 또한 등장할 것으로 기대


