

Adding Conditional Control to Text-to-Image Diffusion Models
Introduction
Does previous prompt-based control satisfy our needs?
1.
데이터셋
a.
Specific-domain에서 사용 가능한 데이터 규모가 일반적인 이미지-텍스트 dataset 만큼 크지 않음
b.
적은 데이터에서도 overfitting 막고, 일반적인 생성 능력 잃지 않는 학습 방법 필요
2.
인프라
a.
large computation cluster 불가능한 경우 많음
b.
일반적으로 가용할 수 있는 device(GPU 1개 등)에서 large model을 빠르게 optimize 할 수 있어야 함
3.
다양한 input
a.
이미지 처리에는 pose-to-human, depth-to-image 등 다양한 task가 있고, 이러한 task-specific input condition을 cover할 수 있는 end-to-end learning method 필요

Method
1. ControlNet
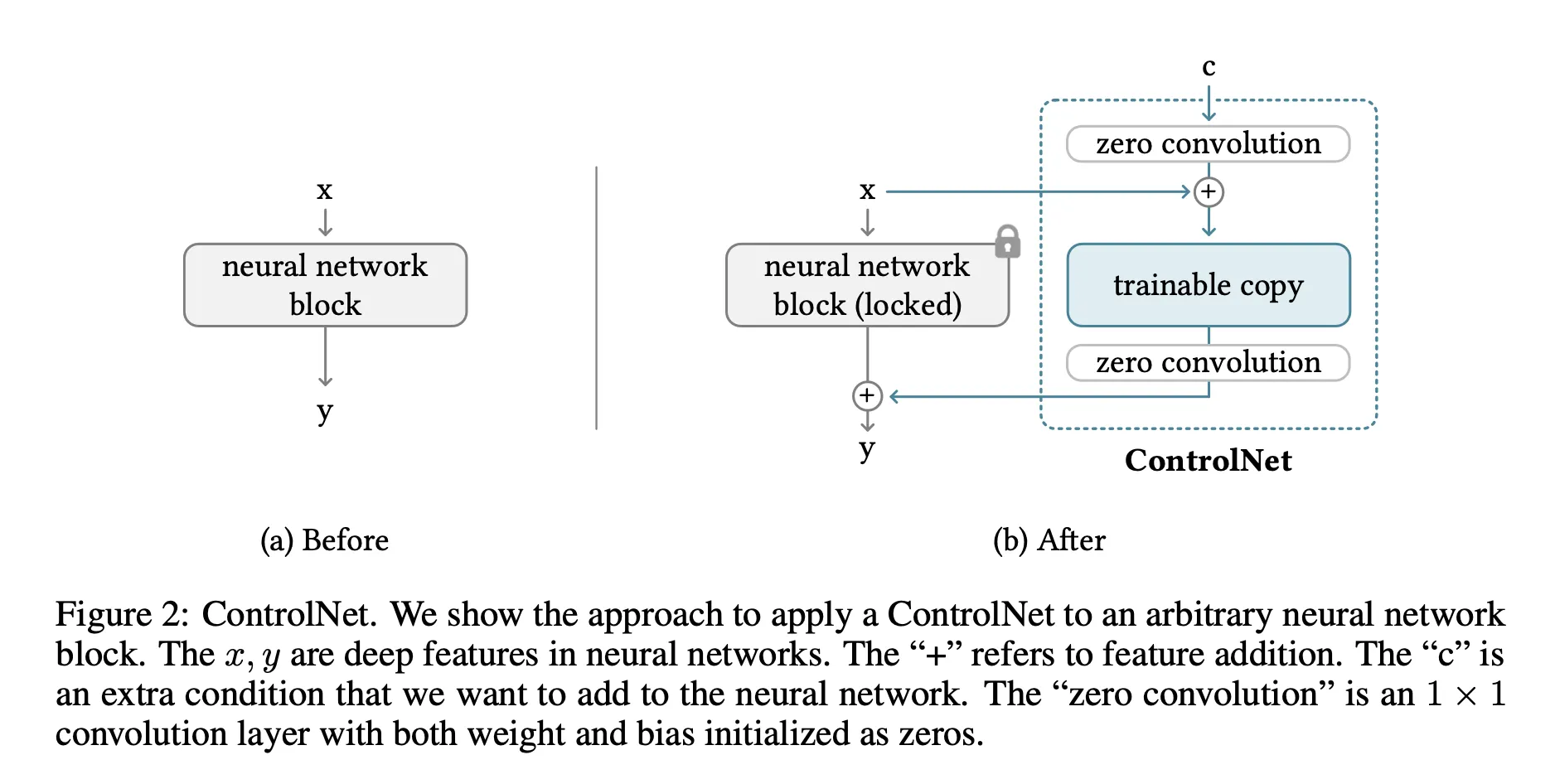
•
locked copy
◦
pre-trained network, locked
◦
avoid overfitting, preserve the production-ready quality
•
trainable copy
•
zero convolution
◦
1x1 convolution layer with both weight and bias initialized as zeros
◦
deep feature에 새로운 noise 추가하지 않기 때문에, 추가한 layer를 scratch(random init) 부터 학습할 때 보다 더 빠르게 fine tuning 가능
•
zero init 하면 update 안 되는거 아니냐? 수식 → 논문
2. ControlNet in Image Diffusion Model


diffusion model
stable diffusion
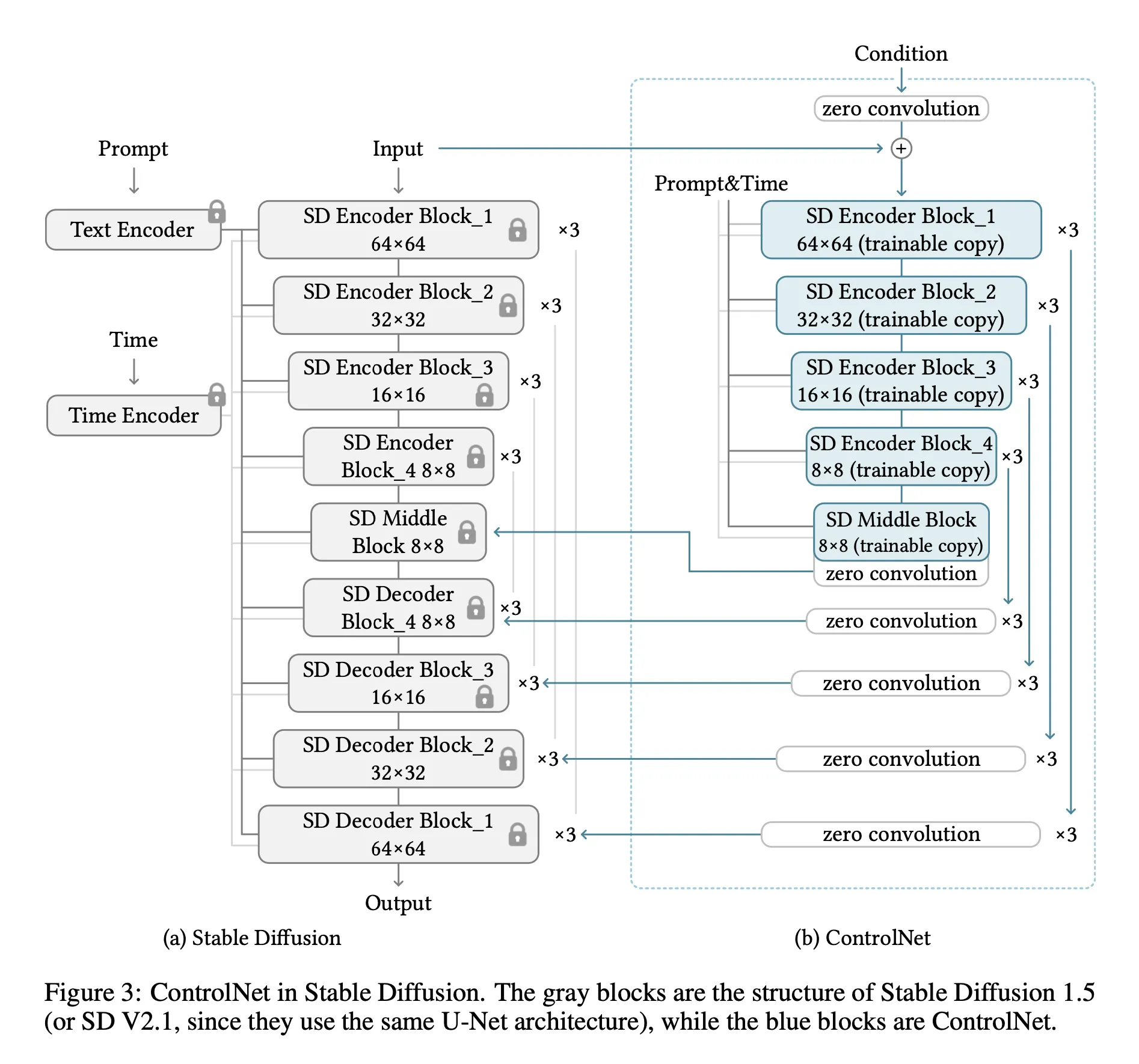
•
locked original network는 update 되지 않고, 추가한 ControlNet 만 update
◦
기존보다 적은 cost
→ GPU memory, training time 감소 → 인프라 문제 해결
◦
freeze 한 network 덕분에 기존 생성 능력 잃지 않고 적은 데이터셋 만으로 fine tuning 가능
→ 데이터 문제 해결
•
Prompt 외에 Condition input 처리 가능 → 다양한 input 문제 해결
Implementation
•
default prompt : “a professional, detailed, high-quality image”
•
Automatic prompt : default prompt로 만든 이미지 → BLIP(image captioning model) 이용해 prompt 생성
•
User prompt : user가 만들어서 줌
1. Canny Edge
2.Hough Line
3. HED Boundary
4.User Sketching
5.Human Pose
6.Semantic Segmentation
Depth
Normal Maps
Cartoon Line Drawing