

Dataset Split
•
그래프를 어떻게 training/validation/test로 나눌 것인가?
•
그래프의 node들은 서로 independence하지 않음

Splitting Graph: Transductive setting
•
전체 그래프를 쓰되 training/valdiation/test 별로 다른 노드만 씀
•
node/edge prediction task에만 사용 가능

Splitting Graph: Inductive setting
•
그래프 자체를 분리하여 나눔
•
unseen graph에도 generalize 되어야 함
•
GraphSAGE?
•
node/edge/graph task에 적용 가능


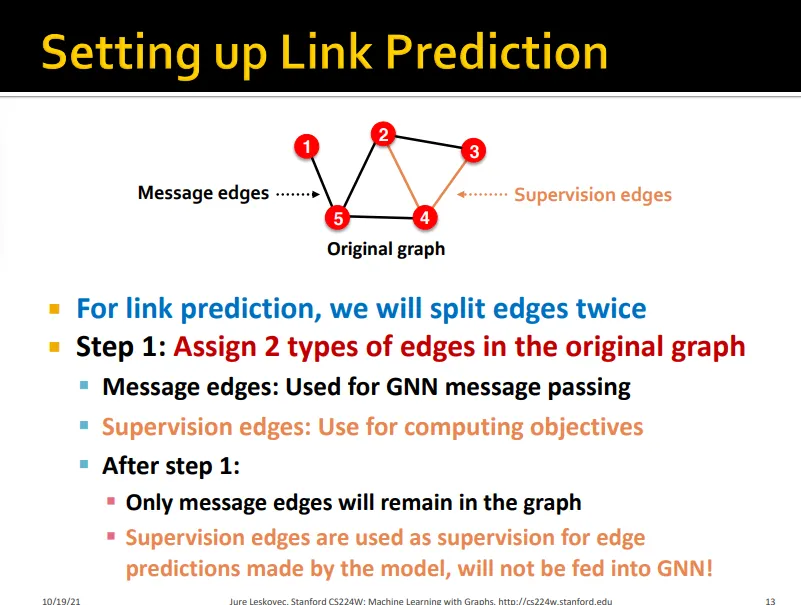
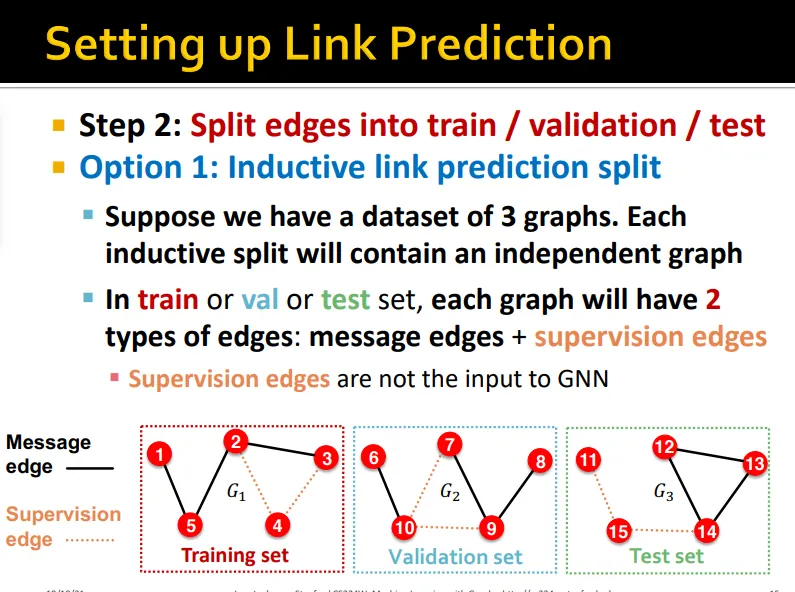
Link Prediction: Inductive split
•
예측할 link를 supervision edge로 정의
•
inductive split 수행
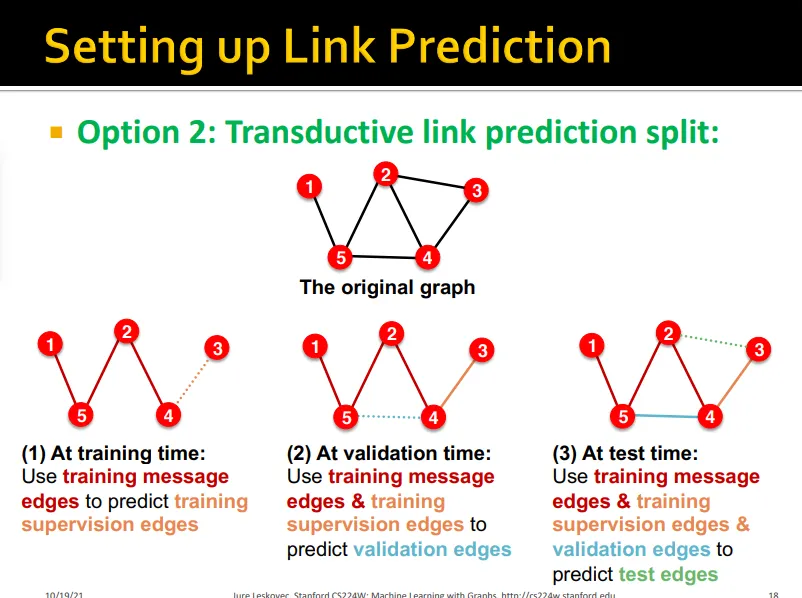
Link Prediction: Transductive split
•
training/validation/test 모두 같은 그래프를 사용하되 다른 supervision edge를 예측함
•
training 때는 training supervision edge 예측
•
validation 때는 training message edges & training supervision edge로 validation edge 예측
•
test 때는 validation edge까지 포함해 test edge를 예측
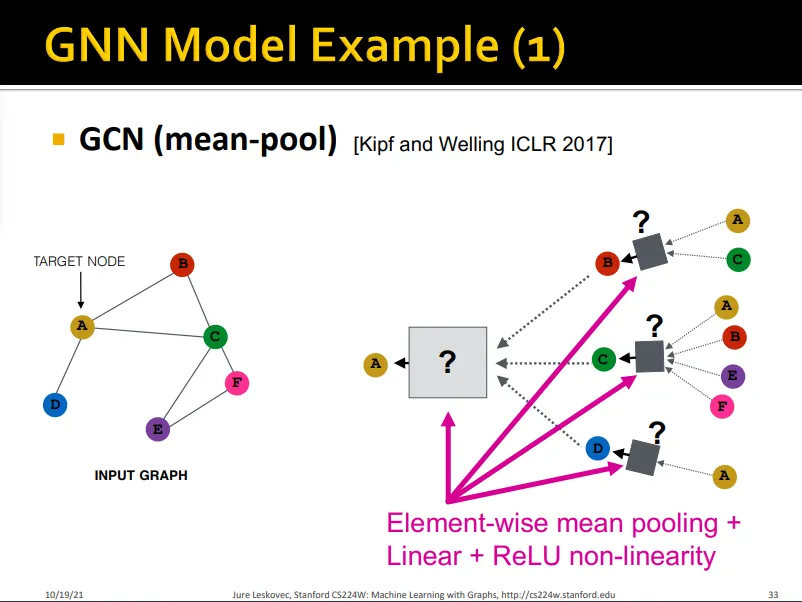
GNN Models
GCN
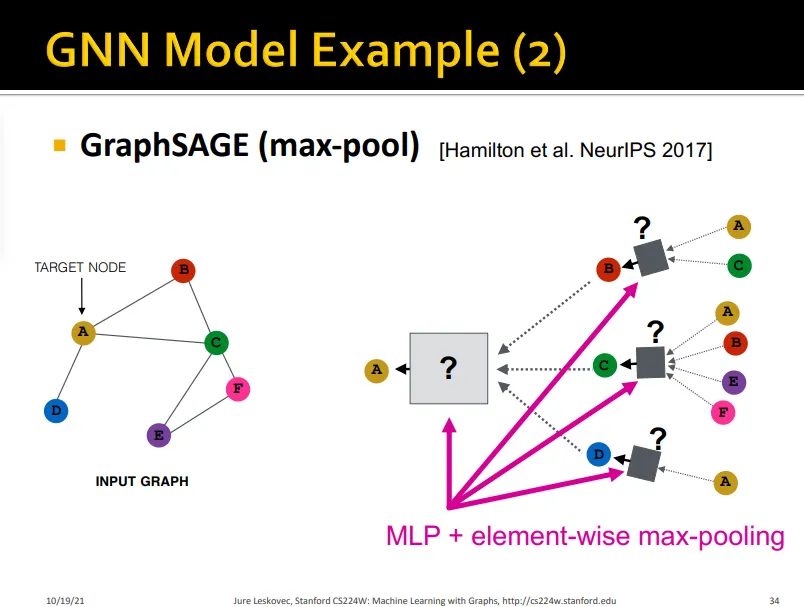
GraphSAGE
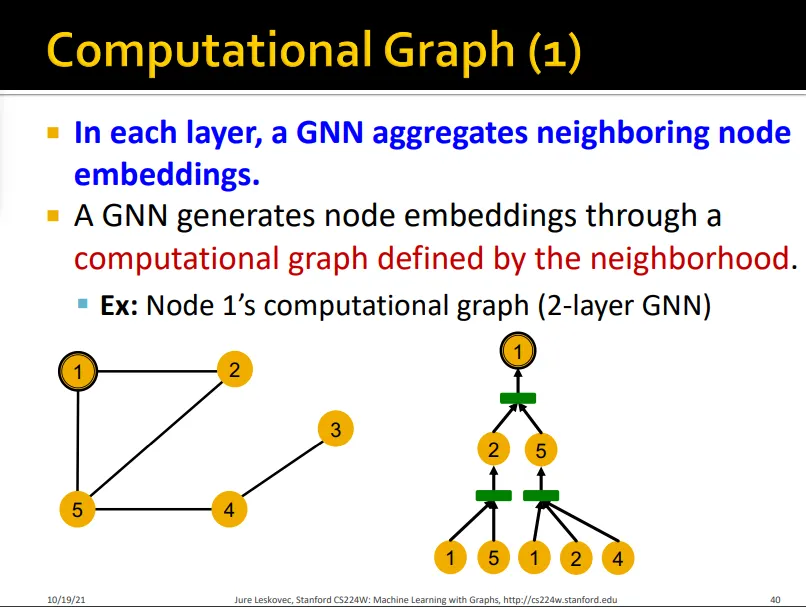
Computational Graph
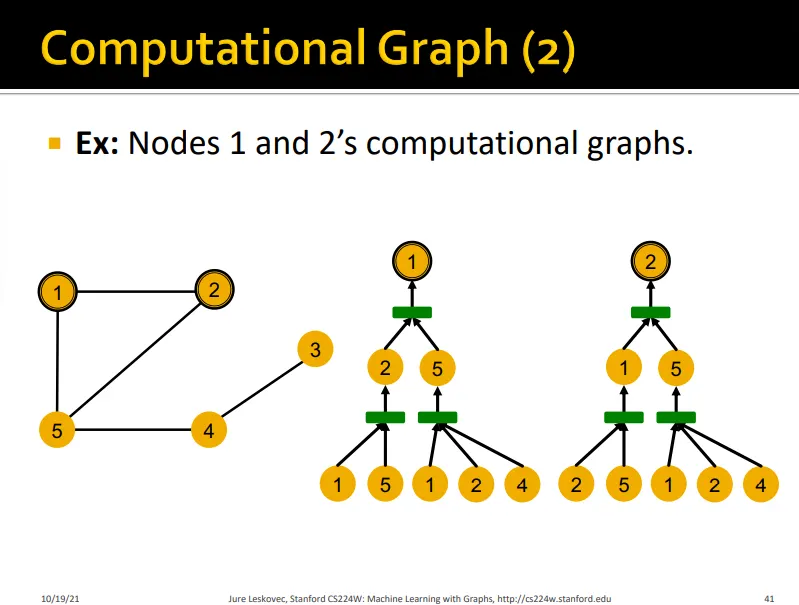
•
여기서 노란색 노드들은 모두 같은 feature를 갖고 있음
•
node 1과 2의 computational graph는 동일함
•
GNN은 노드 1과 2에 대해 동일한 embedding을 만들어 낼 것
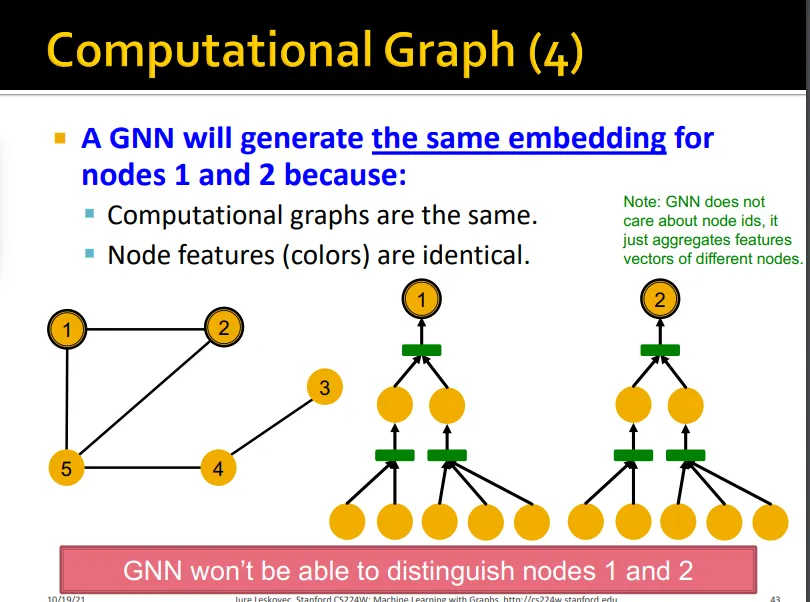
•
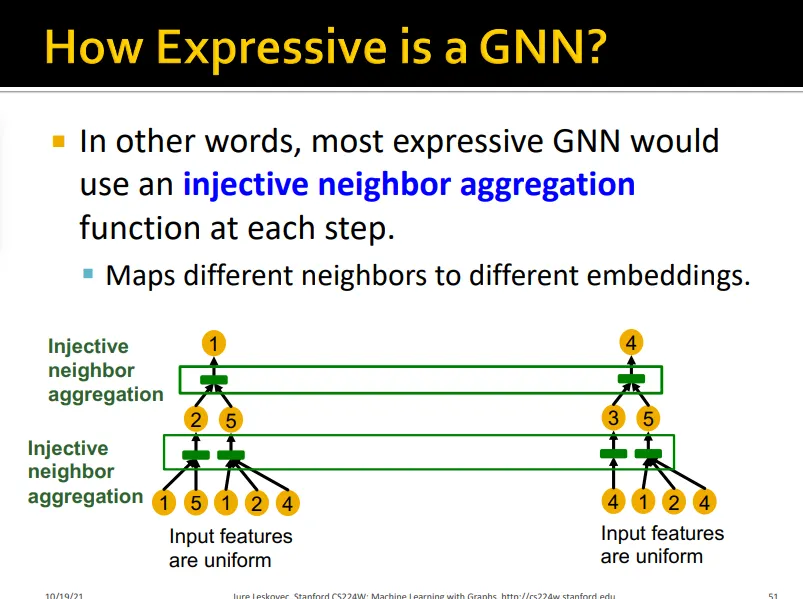
Local neighborhood에 따라 다른 computational graph가 생성됨
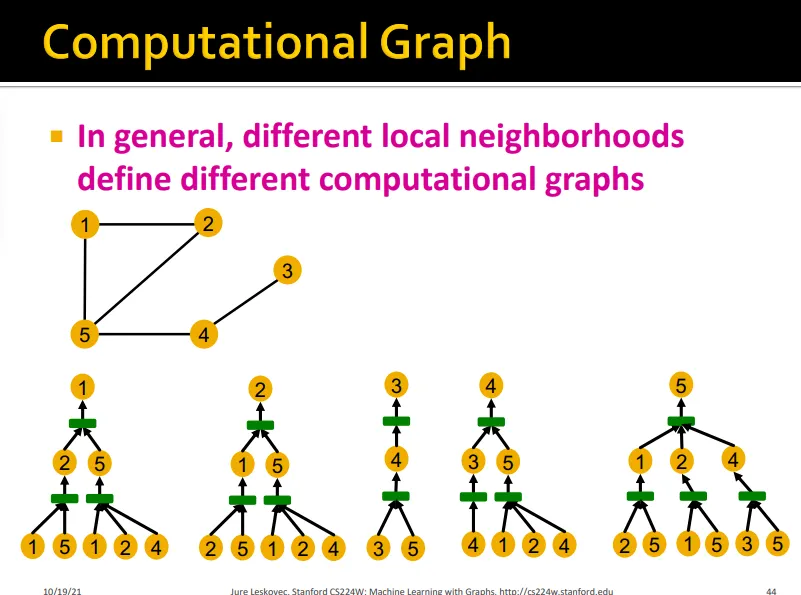
•
expressive GNN 모델은 서로 다른 rooted subtree를 다른 node embedding으로 표현할 수 있어야 함
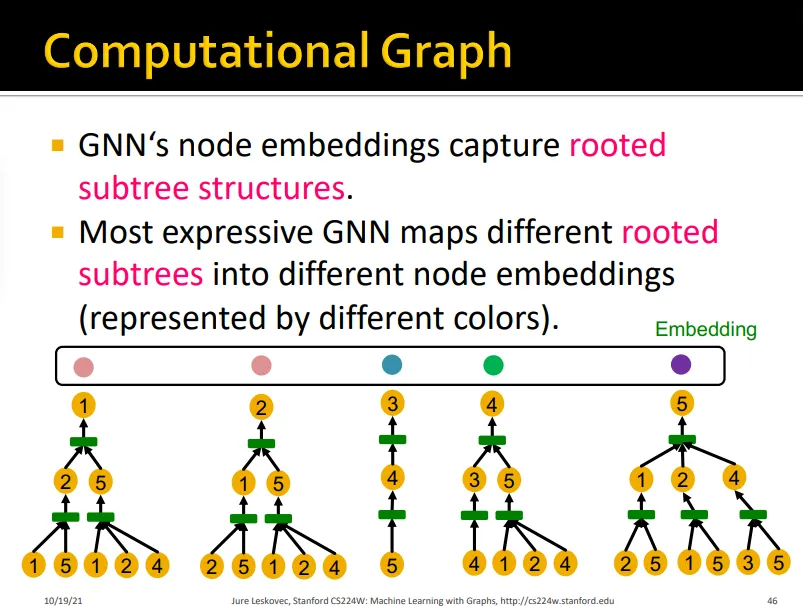
•
일대일로 subtree를 서로 다른 node embedding에 mapping해주어야 expressive한 GNN
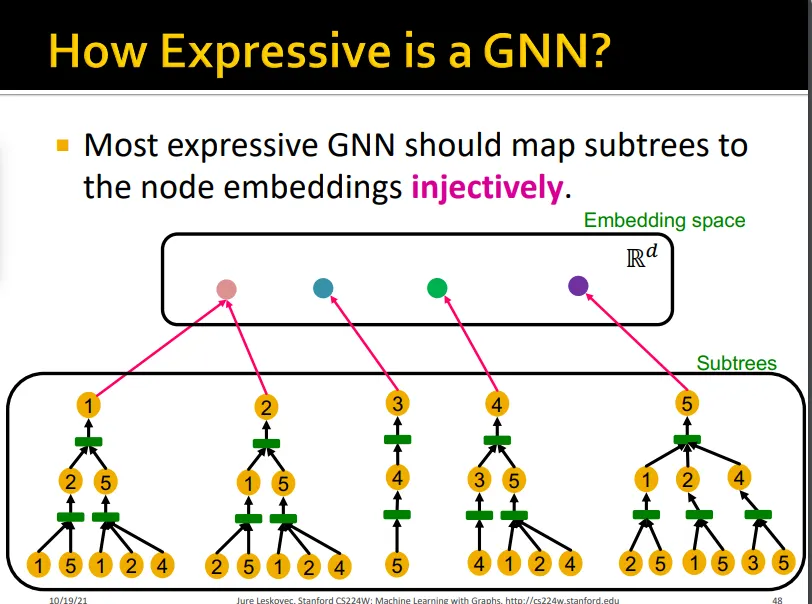
•
rooted subtree를 구분하기 위해서는 GNN의 aggregation이 neighboring information을 잘 담고 있어야 함
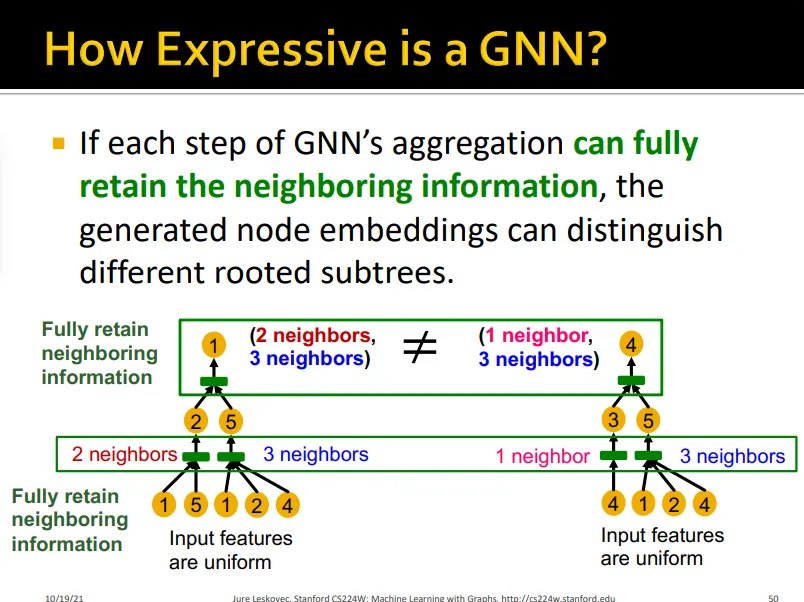
Neighbor Aggregation
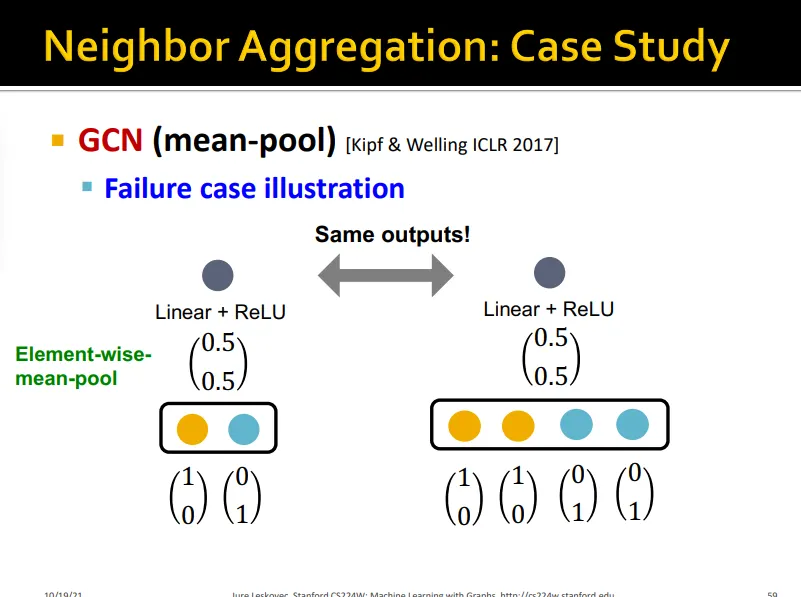
Case of GCN
•
Mean pooling
•
한계: 아래와 같이 같은 color proportion이면 구분하지 못함

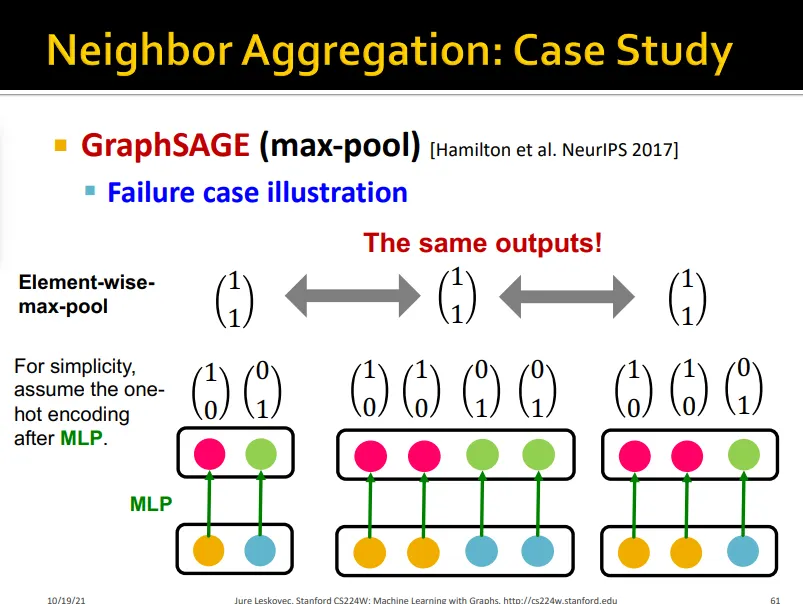
Case of GraphSAGE
•
Max pooling
•
limitation: 서로 다른 color set들로 구성된 multi-set을 구분하지 못함

•
GCN과 GraphSAGE의 aggregation function은 injective 하지 않다고 할 수 있음

Designing Expressive GNN

Case of GIN

•
앞서 나왔던 color refinement algorithm과 유사

•
Aggregate과 hash function이 MLP와 GINConv로 대체

•
WL graph kernel은 거의 모든 그래프를 구분할 수 있음
•
GIN도 마찬가지의 expressiveness를 가짐

Summary
•
Injective multi-set function을 찾고자 함
•
mean-/max-pooling 이 아닌 sum pooling을 사용해야 함
