

일반적인 task 수행 능력 향상
1. Model
1) Size Up
•
LoRA, QLoRA 통해 13B 이상의 모델도 테스트하면 좋을 듯
◦
LLaVA에 LoRA 코드 공개되어 있음
2) Backbone
•
Polyglot-ko 기반
◦
▪
WizardLM으로 데이터셋 퀄리티를 Alpaca 보다 향상
•
Polyglot-ko 기반 모델을 LLaVA에 적용할 때 참고할 코드
•
데모 테스트 통해 적합한 모델 선택
3) New Model
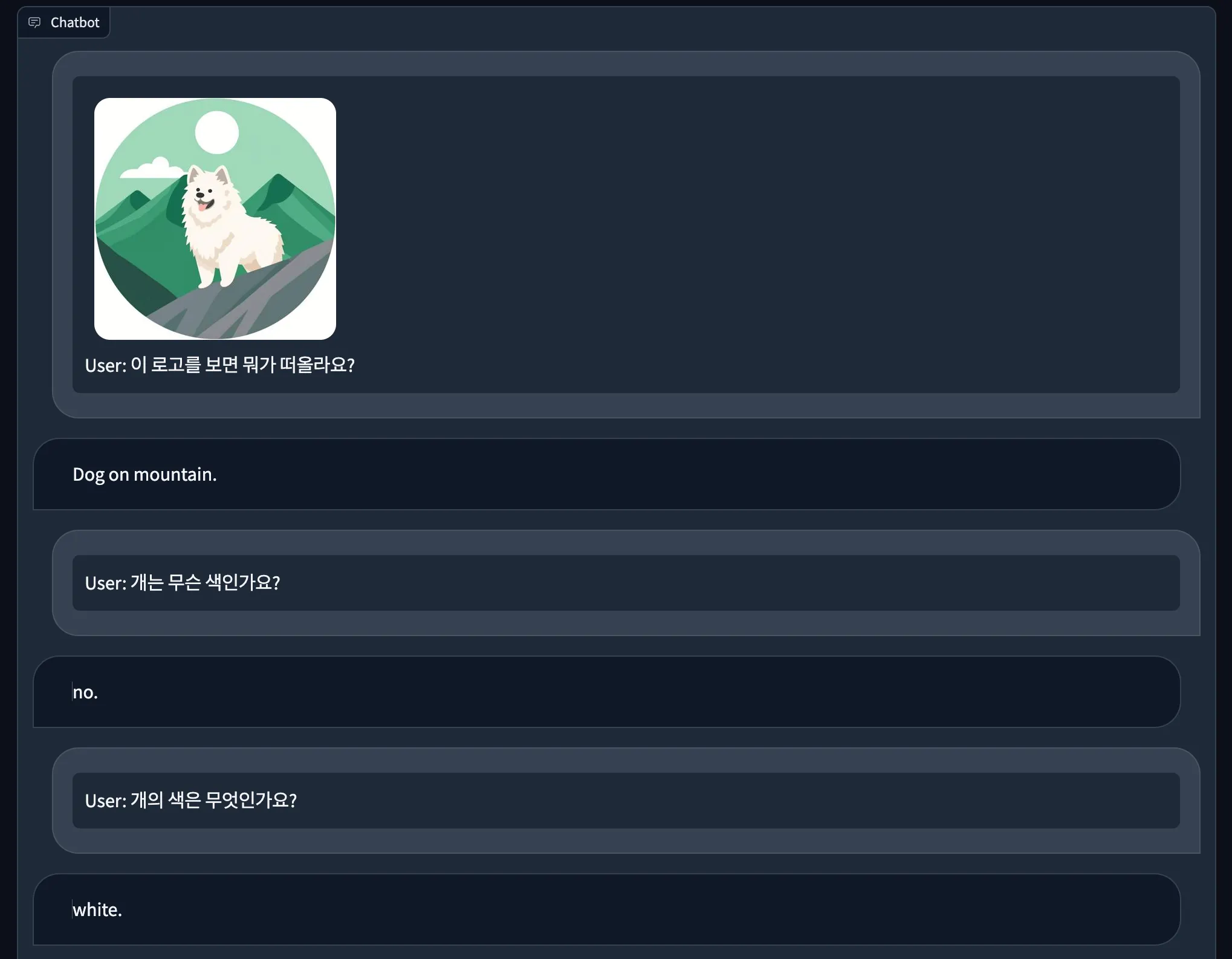
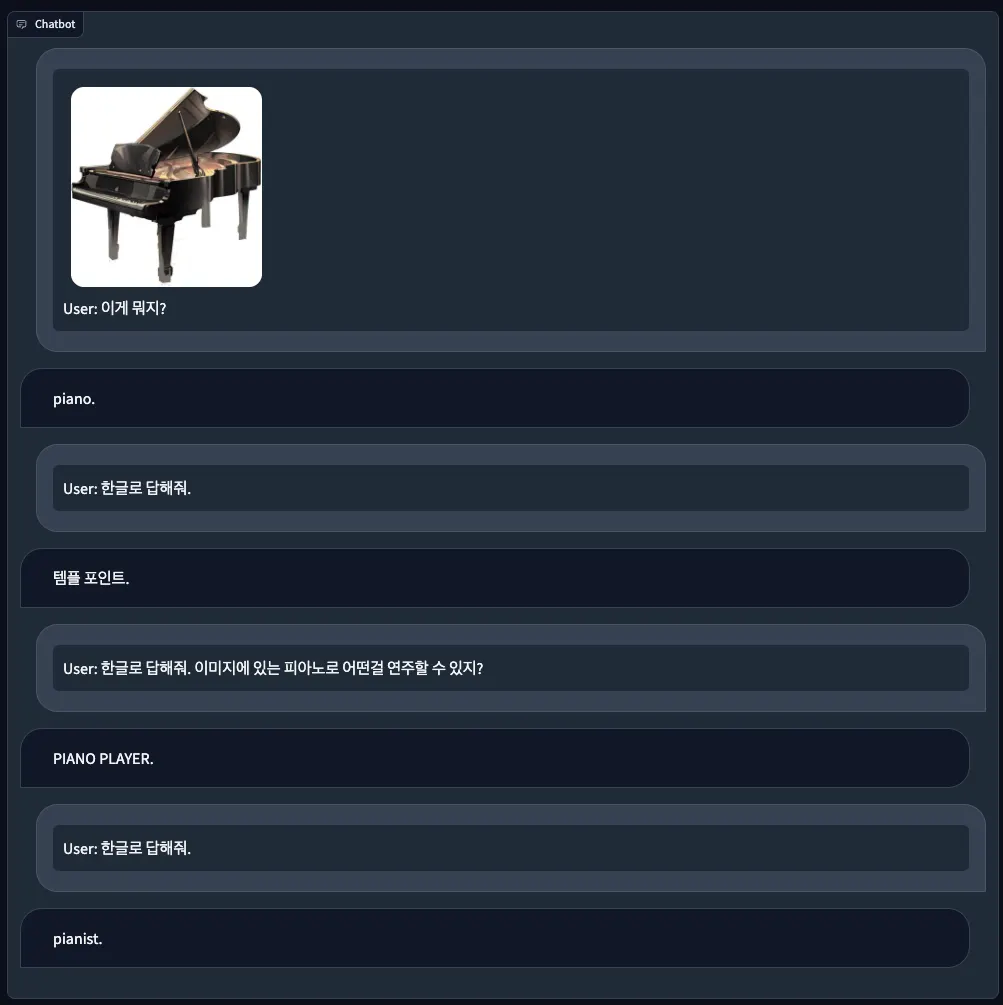
2. Dataset
1) Instruction 데이터 퀄리티 향상
•
WizardLM
◦
영어 instruction을 한국어 고퀄 instruction으로 만들어주는 코드
•
KoLLaVA 데이터셋의 퀄리티 향상
2) AI-Hub에서 특정 데이터 가져와서 Instruction 데이터로 변환
•
◦
이미지와 이미지에 대한 질문과 대답으로 구성된 시각정보 기반 질의응답(VQA) 데이터셋
◦
예시
▪
질문
{
"question_id": "114000",
"image_id": "1-114",
"question": "유리 그릇에 어떤 종류의 기구가 있습니까?"
},
{
"question_id": "114001",
"image_id": "1-114",
"question": "포크가 있습니까?"
},
{
"question_id": "114002",
"image_id": "1-114",
"question": "샌드위치의 재료는 무엇입니까?"
},
{
"question_id": "114003",
"image_id": "1-114",
"question": "재료가 샌드위치 두 개이상 만들기에 충분합니까?"
},
{
"question_id": "114004",
"image_id": "1-114",
"question": "빵에 바른 빨간색 소스는 무엇입니까?"
},
{
"question_id": "118000",
"image_id": "1-118",
"question": "그릇에 포도가 있습니까?"
},
{
"question_id": "118001",
"image_id": "1-118",
"question": "햇빛이 비치고 있습니까?"
},
{
"question_id": "118002",
"image_id": "1-118",
"question": "그릇에 몇 가지 과일이 있습니까?"
},
{
"question_id": "118003",
"image_id": "1-118",
"question": "그릇의 기본 색상은 무엇입니까?"
},
JavaScript
복사
•
답변
{
"question_id": "114000",
"image_id": "1-114",
"multiple_choice_answer": "포크",
"answer_confidence": "yes"
},
{
"question_id": "114001",
"image_id": "1-114",
"multiple_choice_answer": "예",
"answer_confidence": "yes"
},
{
"question_id": "114002",
"image_id": "1-114",
"multiple_choice_answer": "참치, 마요네즈, 파슬리",
"answer_confidence": "maybe"
},
{
"question_id": "114003",
"image_id": "1-114",
"multiple_choice_answer": "예",
"answer_confidence": "yes"
},
{
"question_id": "114004",
"image_id": "1-114",
"multiple_choice_answer": "케첩",
"answer_confidence": "maybe"
},
{
"question_id": "118000",
"image_id": "1-118",
"multiple_choice_answer": "아니요",
"answer_confidence": "yes"
},
{
"question_id": "118001",
"image_id": "1-118",
"multiple_choice_answer": "예",
"answer_confidence": "yes"
},
{
"question_id": "118002",
"image_id": "1-118",
"multiple_choice_answer": "3",
"answer_confidence": "yes"
},
{
"question_id": "118003",
"image_id": "1-118",
"multiple_choice_answer": "푸른색",
"answer_confidence": "yes"
},
JavaScript
복사
•
질문 및 답변이 단답인 경우가 많아 개선 필요
3) 평가방법
에트리
◦
챗지피티 → 한국어 대형언어모델
▪
시각 지능
•
언어모델 + 시각 융합
•
목표 : general
stable diffusion
•
deepL로 하고 있었음
▪
연구원
•
목표 : 논문(탑티어 학회)
•
결과물
▪
논문 생각이 있는지?
에트리 카이스트 황성주 교수님 파트타임 박사과정 - 이용완
•
오픈 소스 기여
◦
최종 목적 : 한국어 기반 멀티모달 허깅페이스 업로드
•
논문
◦
01099496166