개요
•
기존 Foundation model의 문제점
◦
Inference의 computation 고려 X
◦
성능 향상에 초점 맞추며 파라미터 늘림
◦
현실적으로 일반적인 기업에서 서비스 거의 불가능
→ 추론 서비스를 고려한 Foundation model 필요
요약
•
모델
◦
4가지 버전의 모델 공개 (6.7B, 13B, 32.5B, 65.2B)
◦
13B 모델은 Single GPU(V100-32G)에 실행 가능
◦
최신 모델 연구를 반영해 Transformer 구조 수정
•
성능
◦
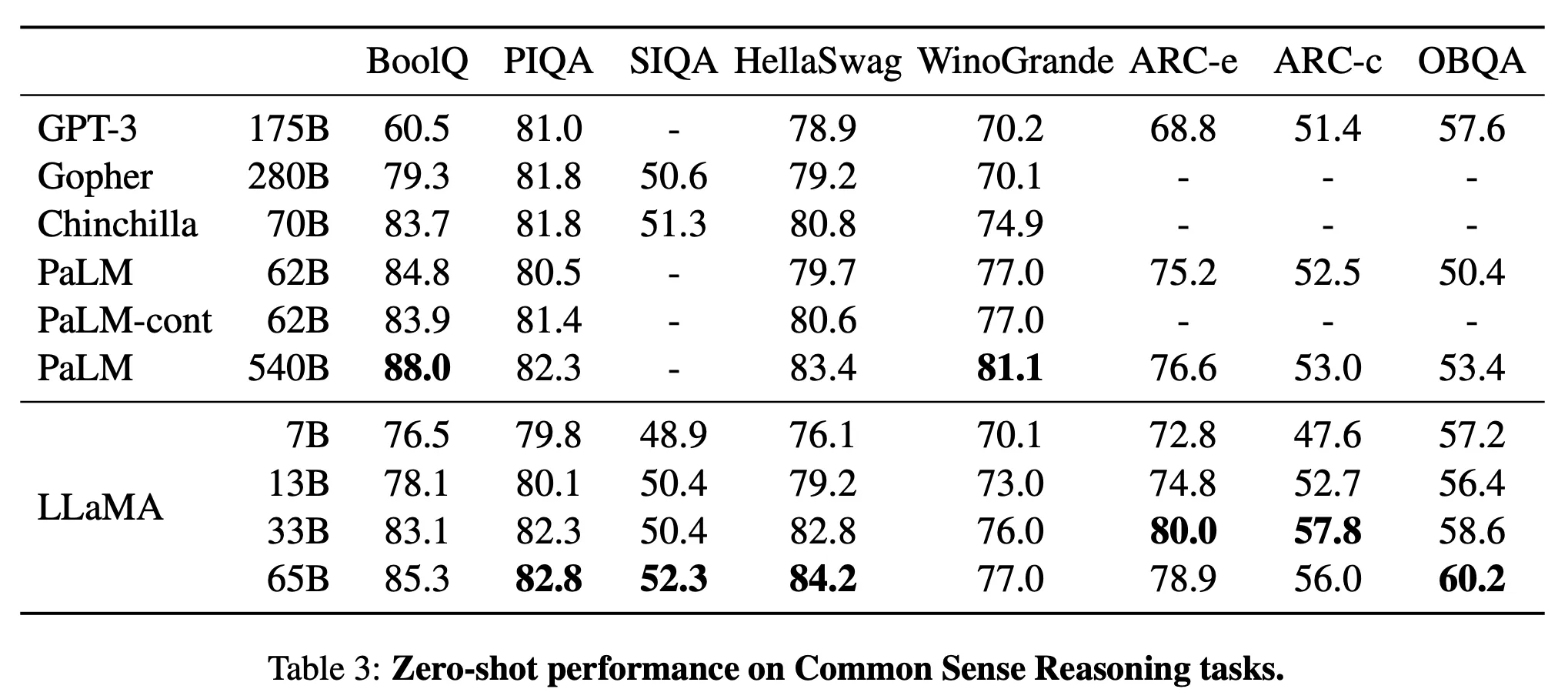
LLaMA(13B) : GPT3(175B)보다 1/10 이상 모델 사이즈가 작지만, 모든 벤치마크에서 GPT3(175B)를 압도하는 성능 보임
◦
LLaMA(65B) : DeepMind의 Chinchilla(70B)과 Google Research의 PaLM(540B)와 같은 LLM 만큼 경쟁력이 있음
•
데이터
◦
공개 데이터만으로 학습
의의
•
이미지 생성 분야에서 Stable diffusion의 코드와 파라미터가 공개되며 급격한 발전을 이루었듯이,
언어 모델 분야에서 LLaMA가 공개되며 빠른 변화를 가져옴